
Résumez cet article avec :
- Entrypoint.AI est une plateforme d'optimisation de l'IA pour les modèles de langage propriétaires et open source, qui propose une approche sans code pour les affiner. .
- IA ouverte fournit une API simple pour affiner les modèles GPT-3.5 et GPT-4, permettant ainsi un entraînement personnalisé sur des ensembles de données spécifiques. .
- Utilisez ces données de préférences humaines pour affiner le modèle grâce à l'apprentissage par renforcement.
- Alors que l'IA générative fait partie intégrante de divers domaines, il est essentiel de peaufiner les grands modèles de langage (LLM) pour optimiser les performances et adapter les modèles à des cas d'utilisation spécifiques.
- Eden AI permet d'affiner les modèles d'IA de plusieurs fournisseurs, permettant aux utilisateurs de personnaliser leurs modèles pour des tâches spécifiques.
Alors que l'IA générative fait partie intégrante de divers domaines, il est essentiel de peaufiner les grands modèles de langage (LLM) pour optimiser les performances et adapter les modèles à des cas d'utilisation spécifiques. En améliorant la précision et la pertinence, les ajustements garantissent que l'IA s'aligne sur des exigences uniques. Cet article présente les 10 meilleurs outils et pratiques pour rationaliser le processus et optimiser les résultats.
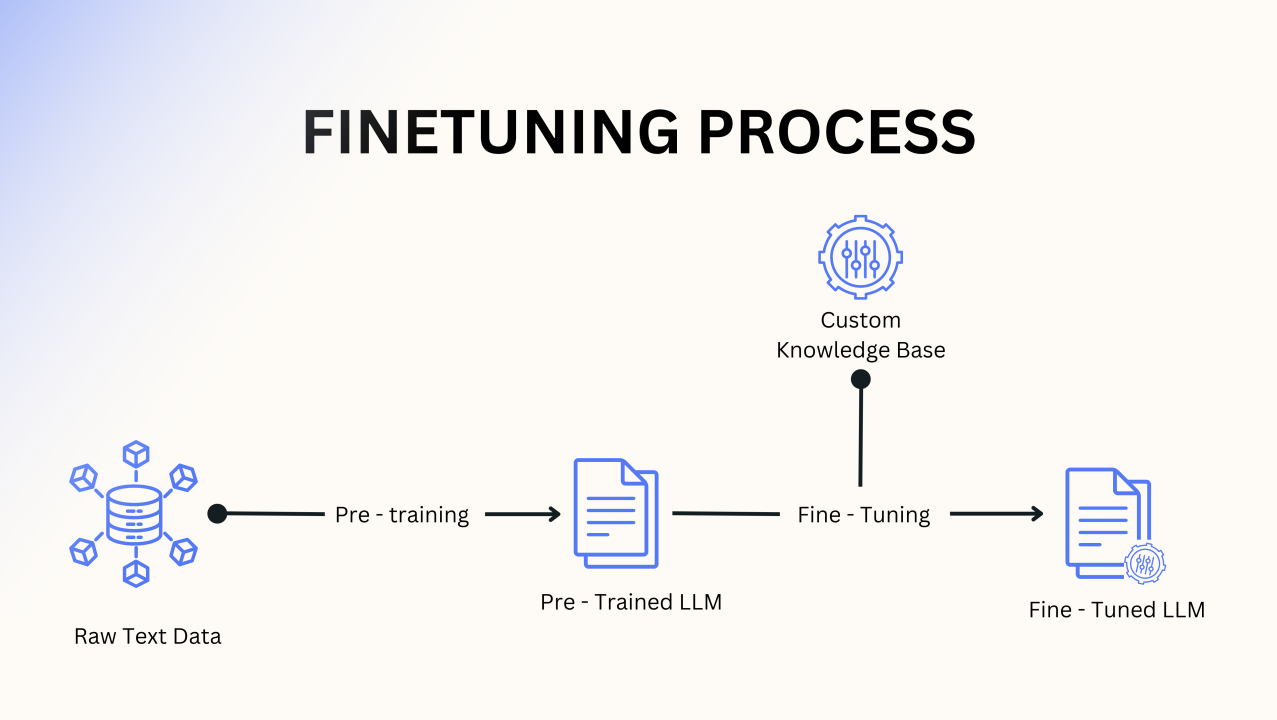
Qu'est-ce que Finetuning LLM ?
Réglage fin en apprentissage automatique, c'est une technique qui consiste à adapter un Modèle de langage étendu (LLM) pour effectuer plus efficacement une tâche spécifique ou dans un domaine particulier.
Réglage fin est l'un des moyens les plus puissants et les plus permanents de personnaliser les LLM. Elle diffère des autres techniques de personnalisation en ce sens qu'elle modifie les paramètres du modèle grâce à une formation supplémentaire, intégrant des connaissances spécialisées directement dans le modèle.
Cependant, cela nécessite plus de temps, de ressources et d'expertise par rapport à des techniques de personnalisation plus simples telles que l'ingénierie rapide.
Alors que l'incitation peut pousser un LLM dans la bonne direction, le réglage précis offre un moyen beaucoup plus fiable d'atteindre les résultats souhaités, en réduisant le nombre de problèmes liés à des tâches spécifiques.
Construire un modèle de base à partir de zéro est une tâche monumentale qui nécessite de vastes ressources et données. Le réglage, cependant, commence par un LLM déjà formé et vous permet de l'adapter à vos besoins à l'aide de vos propres données.
Cela permet d'obtenir des performances d'IA plus précises et spécifiques à des tâches sans les coûts de calcul astronomiques liés à un démarrage à la case départ.
La plupart des LLM modernes, tels que ChatGPT, Claude et Llama, sont conçus pour être polyvalents. Ils sont des généralistes impressionnants, mais ils ont tendance à manquer d'expertise approfondie dans des domaines spécialisés, tels que la recherche pharmaceutique ou les documents juridiques internes d'une entreprise.
Fine-tuning comble cette lacune en ajoutant une couche de connaissances spécialisées, améliorant ainsi leurs performances dans ces domaines.
Méthodes pour personnaliser un LLM
Comme nous l'avons déjà dit, le réglage fin implique la modification d'un LLM pré-entraîné afin d'améliorer ses performances sur des tâches ou des ensembles de données spécifiques, mais il existe d'autres approches pour personnaliser les LLM, notamment :

1. Ingénierie rapide
Ingénierie rapide consiste à élaborer des instructions spécifiques et soigneusement structurées pour orienter la sortie du modèle dans la direction souhaitée. En ajustant le libellé, la structure ou en fournissant un contexte supplémentaire dans l'invite, les utilisateurs peuvent extraire des réponses plus pertinentes, détaillées et précises du modèle.
Il s'agit d'une pratique clé pour tirer parti efficacement des LLM sans modifier le modèle lui-même. Cela peut être particulièrement utile lorsque vous essayez de faire comprendre au modèle des nuances, telles que le ton, le style ou des instructions spécifiques qui doivent être suivies pour mener à bien la tâche.
- Bon pour: Tester des cas d'utilisation de base, déploiement rapide.
- Restrictions: Limité par la taille de la fenêtre contextuelle, moins fiable pour les tâches complexes.
2. Génération augmentée par récupération (RAG)
Génération augmentée par récupération (RAG) combine un LLM avec une base de connaissances ou une base de données externe, permettant au modèle de récupérer et d'intégrer des données en temps réel ou très spécifiques qu'il n'a peut-être pas rencontrées lors de sa formation.
Le modèle extrait d'abord les documents, articles ou faits pertinents de la base de données avant de générer une réponse, combinant ainsi efficacement la génération à une étape de recherche de connaissances. Cela réduit la probabilité que le modèle « hallucine » des informations incorrectes ou fabriquées, en particulier lorsqu'il est interrogé sur des faits autres que ses données d'entraînement.
- Bon pour: introduction de nouvelles informations qui ne figurent pas dans les données d'entraînement du modèle.
- Restrictions: Inefficace pour réduire l'utilisation des jetons ou définir des sorties structurées.
3. Réglage fin
Réglage fin implique la formation d'un LLM préexistant sur un ensemble de données spécifique afin d'améliorer ses performances pour certaines tâches ou certains domaines. Le réglage fin permet de personnaliser le style de réponse, la précision et le comportement du modèle, le rendant ainsi plus adapté à des cas d'utilisation particuliers.
Le réglage fin permet d'adapter un modèle pour qu'il soit performant dans des domaines particuliers, tels que les diagnostics médicaux, la rédaction technique, le service client ou l'analyse juridique. En outre, le réglage fin permet d'ajuster le ton, le style et le comportement du modèle en fonction d'objectifs spécifiques ou de normes de l'entreprise.
- Bon pour: Enseignement de tâches complexes, personnalisation de la structure et du style de sortie.
- Restrictions: Ne convient pas à l'ajout de connaissances entièrement nouvelles.
4. Apprentissage par renforcement avec feedback humain (RLHF)
Apprentissage par renforcement avec feedback humain (RLHF) utilise des commentaires sélectionnés par l'homme pour améliorer les réponses des modèles, en particulier pour les tâches impliquant des décisions subjectives ou stylistiques.
La RLHF peut affiner les performances du modèle en le récompensant pour avoir généré des résultats qui correspondent mieux aux attentes humaines. Il s'agit d'une forme d'amélioration itérative qui est souvent considérée comme un sous-outil de réglage.
- Bon pour: tâches qui impliquent un jugement subjectif, telles que les agents conversationnels, la génération de contenu ou la rédaction créative. Il est également utile pour aligner le comportement du modèle sur les préférences spécifiques des utilisateurs ou les directives éthiques.
- Restrictions: Nécessite une boucle de feedback cohérente et de haute qualité, ce qui peut prendre beaucoup de temps et de ressources. Le RLHF peut ne pas être efficace pour les tâches hautement techniques où la précision est plus importante que l'alignement subjectif.
Méthodes de réglage fin
Il existe plusieurs méthodes pour affiner un LLM, mais deux approches importantes ont vu le jour : l'apprentissage par renforcement avec feedback humain (RLHF) et l'apprentissage supervisé.
1. Apprentissage par renforcement avec feedback humain (RLHF)
Lorsque la sortie d'un LLM est complexe et difficile à décrire pour les utilisateurs, l'approche RLHF peut s'avérer très efficace. Cette méthode implique l'utilisation d'un ensemble de données de préférences humaines pour ajuster le modèle.
Principales étapes de la RLHF
La force de la RLHF réside dans sa capacité à capturer des commentaires et des préférences humains nuancés, même pour les sorties difficiles à articuler. En tirant des enseignements directement des choix humains, le modèle peut être façonné pour produire des résultats plus significatifs et plus utiles pour les utilisateurs finaux.
- Recueillez les commentaires des humains sur les résultats du modèle. Ce feedback prend la forme de choix entre différentes options de sortie.
- Utilisez ces données de préférences humaines pour affiner le modèle grâce à l'apprentissage par renforcement. Le modèle apprend à générer des résultats qui correspondent davantage aux préférences humaines.
Exemple RLHF
input_text : Créez une description pour Plantation Palms.
candidate_0 : Amusez-vous au soleil à Gulf Shores.
candidate_1 : Une oasis paisible de beauté naturelle
choix : 0
2. Enseignement supervisé
En revanche, l'approche d'apprentissage supervisé pour affiner les LLM convient mieux aux modèles dont les résultats sont relativement simples et faciles à définir.
Méthode d'apprentissage supervisé
L'approche d'apprentissage supervisé est particulièrement utile lorsque le résultat souhaité peut être clairement spécifié, par exemple pour des tâches telles que la classification de texte ou la génération de données structurées. En fournissant au modèle des paires d'entrées-sorties exemplaires, il peut apprendre à reproduire de manière fiable les résultats attendus.
- Création d'un ensemble de données d'exemples étiquetés qui illustrent le résultat souhaité du modèle.
- Ajustement du LLM à l'aide de ces exemples étiquetés, permettant au modèle d'apprendre le mappage entre les entrées et les sorties cibles.
Exemple d'apprentissage supervisé
Rapide : Classez le texte suivant dans l'une des classes suivantes : [affaires, divertissement].
Texte: Diversifiez votre portefeuille de placements
Réponse : affaires
Le choix entre la RLHF et l'apprentissage supervisé pour affiner un LLM dépend de la complexité des résultats du modèle et de la facilité avec laquelle ils peuvent être définis. La RLHF est la meilleure option lorsque les résultats sont complexes et subjectifs, nécessitant un feedback humain nuancé pour guider l'apprentissage du modèle.
L'apprentissage supervisé, en revanche, brille lorsque les résultats souhaités sont plus simples et peuvent être capturés avec précision dans un ensemble de données étiqueté.
Comment peaufiner les LLMs ?
Le réglage précis d'un modèle pré-entraîné lui permet de se spécialiser dans une tâche spécifique en l'entraînant sur un ensemble de données plus petit et spécifique à la tâche.
Le flux de travail comprend la préparation des données, la formation des modèles, l'évaluation et l'itération, ainsi que le déploiement, chacun de ces éléments contribuant à l'optimisation du modèle pour les applications du monde réel.

1. Préparation des données
La première étape du réglage consiste à préparer des données étiquetées de haute qualité pertinentes pour la tâche. La qualité et la diversité de ces données auront un impact direct sur les performances du modèle affiné.
- Collectez des données étiquet qui représente la tâche que vous souhaitez que le modèle exécute.
- Nettoyez les données en supprimant les incohérences, les doublons et les informations non pertinentes.
- Garantir la diversité dans les données pour couvrir un large éventail d'entrées et de scénarios, ce qui permet au modèle de mieux généraliser.
- Formater les données dans une structure standardisée (par exemple, JSONL) pour assurer la compatibilité avec la plate-forme de réglage.
- Équilibrer l'ensemble de données pour éviter la surreprésentation de certains exemples ou étiquettes.
2. Formation sur les modèles
Au cours de cette étape, vous allez entraîner le modèle sur le jeu de données préparé. Vous devrez choisir les bons hyperparamètres et suivre la progression du modèle pour vous assurer qu'il apprend efficacement la tâche.
- Sélectionnez les hyperparamètres appropriés tels que le taux d'apprentissage, la taille des lots et le nombre d'époques.
- Entraînez le modèle sur les exemples spécifiques à la tâche (généralement 50 à 1 000 échantillons pour les petites tâches).
- Surveiller le processus de formation détecter les signes de surajustement ou de sous-ajustement en analysant les mesures de perte et de précision.
- Ajuster les hyperparamètres comme le taux d'apprentissage ou la taille du lot en fonction des performances du modèle.
- Testez différentes configurations si le modèle ne s'améliore pas, par exemple en modifiant l'architecture ou l'approche de formation.
3. Évaluation et itération
Une fois le modèle entraîné, évaluez ses performances sur un ensemble de validation pour voir dans quelle mesure il se généralise aux nouvelles données. Les ajustements itératifs contribuent à améliorer la précision et la fiabilité du modèle.
- Evaluer les performances en utilisant des indicateurs tels que la perte d'entraînement, la perte de validation, le score F1 ou la précision spécifique à une tâche (par exemple, précision, rappel).
- Identifier les domaines à améliorer en comparant les performances du modèle au résultat souhaité.
- Affiner le modèle en ajustant les hyperparamètres, en ajoutant d'autres exemples d'entraînement ou en améliorant la qualité des données.
- Répéter sur plusieurs cycles de formation et d'évaluation pour affiner davantage le modèle.
- Testez la robustesse du modèle en veillant à ce qu'il fonctionne bien dans une variété d'entrées et de conditions.
4. Déploiement
Après avoir obtenu des performances satisfaisantes, déployez le modèle affiné dans des applications réelles, en vous assurant qu'il est évolutif et facilement accessible pour les utilisateurs finaux.
- Intégrez le modèle affiné dans votre application ou service via une API optimisée.
- Surveillez les performances du modèle en production pour identifier les problèmes tels que la latence ou les inexactitudes.
- Mettre en place une boucle de feedback pour une amélioration continue, réentraîner le modèle périodiquement à l'aide de nouvelles données ou de commentaires des utilisateurs.
- Garantir l'évolutivité en optimisant le modèle en termes de rapidité et d'efficacité dans les applications en temps réel.
- Sécurisez le déploiement en mettant en œuvre des contrôles d'accès et en surveillant les risques de sécurité potentiels.
Les 10 meilleurs outils de réglage
1. Eden AI


Eden AI est une plateforme d'IA complète permettant aux développeurs de créer, de tester et de déployer efficacement l'IA grâce à un accès unifié aux meilleurs modèles d'IA combiné à un puissant générateur de flux de travail. Eden AI permet d'affiner les modèles d'IA de plusieurs fournisseurs, permettant aux utilisateurs de personnaliser leurs modèles pour des tâches spécifiques.
Caractéristiques principales :
- Assistance multifournisseurs : Ajustez les modèles de différents fournisseurs d'IA, y compris GPT-4o.
- Paramètres personnalisables: Ajustez les époques et la taille de l'ensemble de données pour des résultats personnalisés.
- Gestion simplifiée des données : Importez des ensembles de données (par exemple, CSV) et créez des invites structurées sans effort.
- Interface conviviale: Simplifie le réglage pour tous les niveaux de compétence.
Idéal pour: Eden AI est idéal pour déployer des modèles d'IA personnalisés provenant de plusieurs fournisseurs afin de répondre aux besoins spécifiques à un domaine et d'optimiser les performances.
2. Hugging Face (autotrain)

Hugging Face propose une puissante plateforme open source permettant de peaufiner les modèles pré-entraînés, ce qui en fait une référence pour les praticiens de l'apprentissage automatique.
Caractéristiques principales :
- Prend en charge un large éventail de modèles pré-entraînés sur plusieurs frameworks
- Fournit des bibliothèques complètes pour PyTorch et TensorFlow
- Offre des API de formation et des référentiels de modèles faciles à utiliser
- Supporte diverses techniques de réglage, telles que LoRa et le réglage complet des paramètres
Idéal pour : Chercheurs et développeurs à la recherche d'une solution open source flexible avec une prise en charge étendue des modèles.
3. Poids et biais (Wandb)

Weights & Biases est une plateforme de suivi des expériences et de gestion de modèles conçue pour rationaliser les projets d'apprentissage automatique.
Caractéristiques principales :
- Suivi complet des expériences
- Visualisation des mesures de performance des modèles
- Outils de collaboration pour les projets d'apprentissage automatique en équipe
- Prise en charge de l'optimisation des hyperparamètres
- S'intègre parfaitement aux principaux frameworks de machine learning
Idéal pour : Les équipes et les organisations qui ont besoin d'outils robustes de gestion des expériences et de collaboration.
4. Comète .ml

Comète .ml est une plateforme MLOps qui aide les équipes à suivre les expériences, à gérer les modèles et à visualiser les performances.
Caractéristiques principales :
- Suivi complet des modèles et gestion des versions
- Optimisation automatique des hyperparamètres
- Visualisation des performances du modèle
- Prise en charge de plusieurs frameworks d'apprentissage automatique
Idéal pour : Les organisations qui ont besoin d'une gestion détaillée des modèles et d'un suivi des performances.
5. Entrypoint.AI
Entrypoint.AI est une plateforme d'optimisation de l'IA pour les modèles de langage propriétaires et open source, qui propose une approche sans code pour les affiner.
Principales caractéristiques:
- Gérez les invites, les réglages et les évaluations en un seul endroit.
- Processus de réglage sans code.
- Supporte les LLM de base grâce à des fonctionnalités de réglage intégrées.
Idéal pour: Les utilisateurs recherchent une plateforme moderne sans code pour affiner facilement les modèles d'IA.
Les fournisseurs de Foundation LLM proposent également des fonctionnalités de réglage intégrées directement via leurs API et leurs plateformes, telles que :
6. Réglage fin d'OpenAI
IA ouverte fournit une API simple pour affiner les modèles GPT-3.5 et GPT-4, permettant ainsi un entraînement personnalisé sur des ensembles de données spécifiques.
Principales caractéristiques:
- Ajustement direct du modèle via l'API d'OpenAI.
- Compatible avec les modèles GPT-3.5 et GPT-4.
- Formation personnalisée sur des ensembles de données spécifiques.
- Infrastructure minimale requise.
- Tarification basée sur les jetons d'entrée et de sortie pendant la formation.
Idéal pour: Les développeurs recherchent un processus de réglage simplifié avec un minimum de configuration et d'infrastructure.
7. Mise au point de Claude anthropique
Anthropic Claude se concentre sur l'adaptation de modèles personnalisés grâce à l'intégration d'API, en mettant l'accent sur un comportement éthique et sûr.
Principales caractéristiques:
- Adaptation personnalisée du modèle via une API.
- Concentrez-vous sur le maintien d'un modèle de comportement éthique et sûr.
- Apprentissage contextuel spécifique à un domaine.
- Personnalisation responsable de l'IA.
Idéal pour: Idéal pour les organisations axées sur le déploiement éthique de l'IA avec des besoins spécifiques à un domaine.
8. Google Cloud Vertex AI

Google Cloud Vertex AI fournit une plateforme d'apprentissage automatique de bout en bout pour affiner des modèles tels que PalM et d'autres modèles linguistiques de Google.
Principales caractéristiques:
- Plateforme d'apprentissage automatique de bout en bout.
- Ajustement des modèles linguistiques PalM et Google (Gemini).
- Personnalisation des modèles au niveau de l'entreprise.
- Intégration à l'écosystème ML de Google Cloud.
- Outils de surveillance et de gestion avancés.
Idéal pour: Idéal pour la personnalisation de modèles au niveau de l'entreprise au sein de l'écosystème Google Cloud.
9. Service Azure OpenAI

Azure OpenAI de Microsoft Le service offre des fonctionnalités de réglage de niveau entreprise avec une sécurité et une gouvernance des modèles améliorées.
Principales caractéristiques:
- Supporte plusieurs modèles GPT.
- Fonctionnalités de sécurité et de conformité améliorées.
- Intégration parfaite à l'infrastructure cloud de Microsoft.
- Contrôles d'accès avancés et gouvernance des modèles.
Idéal pour: Les entreprises qui ont besoin de solutions d'IA sécurisées et de niveau professionnel dotées d'une gouvernance robuste.
10. Cohère

Cohère offre une plate-forme puissante pour l'ajustement des modèles linguistiques, permettant une intégration facile en mettant l'accent sur la génération de texte et les intégrations.
Principales caractéristiques:
- Ajustement des modèles pour la génération de texte et les intégrations.
- Modèles: Lampe de commande
- API simple et facile à utiliser
- Excellentes performances sur les tâches de classification.
Idéal pour: Idéal pour les utilisateurs à la recherche d'une API facile à utiliser pour affiner les modèles en mettant l'accent sur les tâches liées au texte.
11. AWS Bedrock

AWS Bedrock propose une gamme d'options de réglage avec des modèles tels que LLama, Cohere et AWS Titan, avec une intégration fluide aux services AWS.
Principales caractéristiques:
- Perfectionner et poursuivre les options de pré-entraînement.
- Support pour des modèles tels que LLama, Cohere et AWS Titan.
- Intégration fluide avec les services AWS.
Idéal pour: Idéal pour les utilisateurs qui font déjà partie de l'écosystème AWS et qui ont besoin de fonctionnalités de réglage continues avec une intégration approfondie.

.png)

