.jpeg)
Résumez cet article avec :
- Eden AI vous permet de choisir parmi plusieurs LLM (GPT-3.5, GPT-4, Claude, etc., selon la disponibilité).
- Utilisez le fournisseur LLM configuré (par exemple OpenAI GPT-4),.
- Dans cet exemple, nous utiliserons GPT-4 pour nous assurer que notre chatbot peut traiter des requêtes complexes.
- LLM (modèle de chat) : Choisissez un grand modèle linguistique pour générer des réponses.
- Par exemple, vous pouvez utiliser OpenAI des modèles pour l'intégration et GPT-4 pour le LLM, ou passez à d'autres fournisseurs ( Cohère , etc.) avec un changement de configuration.
Vous avez déjà voulu parler à vos documents ? La génération RAG (Retrieval-Augmented Generation) rend cela possible en vous permettant utiliser RAG pour discuter avec des PDF grâce à un chatbot qui trouve des réponses à partir de vos fichiers. Dans ce didacticiel, nous montrons aux développeurs (en particulier aux startups et aux PME) comment combiner RAG avec l'API unifiée d'Eden AI pour créer un chatbot alimenté par LLM capable d'interagir avec vos documents PDF, étape par étape.
Qu'est-ce que Génération augmentée par récupération (RAG) ?
Génération augmentée par récupération (RAG) est une technique qui combine de grands modèles de langage (LLM) avec un récupération système pour fournir des réponses précises et contextuelles.
Au lieu de s'appuyer uniquement sur les données d'entraînement d'un LLM (qui peuvent être obsolètes ou hallucinées), RAG complète le modèle avec connaissances externes à partir de vos documents.
Voici comment fonctionne le mécanisme de base :
1. Indexation (ingestion de documents)
Vous chargez vos documents (par exemple des PDF) et vous les divisez en morceaux (morceaux de texte). Chaque morceau est alors converti en une intégration (vecteur) — une représentation numérique capturant une signification sémantique. Ces intégrations vectorielles sont stockées dans un base de données vectorielles (base de données vectorielle) pour une recherche de similarité rapide. Cela prépare un index des connaissances de votre contenu PDF.
2. Récupération
Lorsqu'un utilisateur pose une question, la requête est également transformée en une intégration. Le système compare cela intégration de requêtes par rapport aux vecteurs de documents stockés (généralement par similarité cosinus) à trouvez les morceaux les plus pertinents. Essentiellement, il recherche dans vos données PDF les passages qui sont sémantiquement les plus proches de la question.
3. Génération
Les morceaux de texte récupérés (les passages pertinents de vos PDF) sont ensuite introduits dans un LLM avec la question de l'utilisateur. Le LLM l'utilise contexte augmenté pour générer une réponse fondée sur le contenu de vos documents. De par sa conception, la réponse doit rester factuelle et renvoyer aux données fournies plutôt que d'inventer des choses.
Pour en savoir plus sur le fonctionnement de RAG, consultez notre Guide 2025 de la génération augmentée par récupération (RAG) sur le blog Eden AI.
Qu'est-ce que RAG ajoute aux LLM ?
RAG fournit des connaissances spécifiques et actualisées au modèle au moment de la requête, sans avoir à affiner le LLM.
Ceci est essentiel pour l'interaction avec les documents personnalisés, car cela garantit que les réponses du chatbot sont basées sur vos PDF (données fiables) plutôt que sur la mémoire limitée ou les données d'entraînement du modèle.
Dans un système basé sur RAG, le LLM devient effectivement un moteur de raisonnement qui consulte vos documents pour chaque réponse. C'est très améliore la précision et réduit les hallucinations.
En résumé, RAG vous permet de créer un système RAG pour discuter avec les LLM qui disposent des informations exactes de vos PDF au moment de répondre, ce qui vous permet de parlez à vos documents avec RAG en toute confiance.
Cas d'utilisation professionnels pour le chat en mode RAG avec des PDF
Les chatbots basés sur des chiffons qui peuvent interagir avec les PDF ouvrent de nombreux cas d'utilisation pratiques dans tous les secteurs.
Voici quelques exemples :
1. Accès à la base de connaissances interne :
Les entreprises peuvent créer un chatbot permettant aux employés de consulter les politiques, les manuels ou les guides internes. Au lieu d'effectuer des recherches manuelles dans des PDF et des pages Web, les employés peuvent poser des questions au chatbot et obtenir des réponses précises avec des références, afin d'améliorer la productivité et l'intégration.
2. Conformité réglementaire et recherche juridique :
Les organisations soumises à des réglementations strictes, telles que les finances, la santé et le droit, utilisent des systèmes basés sur RAG pour rationaliser l'accès à des documents de politique denses et en constante évolution. Un assistant alimenté par RAG peut récupérer les dernières règles de conformité, clauses légales ou procédures internes à partir de sources internes et externes.
Chez Eden AI, par exemple, nous avons implémenté un Chatbot juridique qui permet aux utilisateurs de rechercher instantanément via notre documents relatifs à la confidentialité des données et aux conditions d'utilisation, y compris ceux de notre fournisseurs d'API tiers. Au lieu de parcourir plusieurs PDF ou d'essayer de décoder le jargon juridique, les utilisateurs peuvent désormais simplement demander :« Est-ce qu'OpenAI stocke le contenu des utilisateurs via Eden AI ? ».
Cette approche améliore non seulement la transparence et la confiance des utilisateurs, mais s'aligne également sur les efforts de conformité réglementaire tels que GDPR, CCPA, et normes spécifiques à l'industrie.

3. Chatbots d'assistance à la clientèle :
RAG peut améliorer considérablement le support client en transformant la documentation des produits, les FAQ et les guides d'intégration en une base de connaissances consultable. Au lieu de se fier à une recherche par mot clé ou d'attendre un agent d'assistance, les utilisateurs peuvent interroger un chatbot qui extrait des réponses précises à partir de votre contenu.
Par exemple, Eden AI construit un Chatbot Discord alimenté par Rag qui permet aux utilisateurs de poser des questions sur la plateforme, telles que les tarifs, les fournisseurs, les fonctionnalités ou l'utilisation de l'API, et d'obtenir des réponses immédiates et contextuelles à partir de la documentation indexée de l'entreprise.
Les utilisateurs de la communauté Discord peuvent saisir des questions en langage naturel telles que : »Quels fournisseurs d'IA prennent en charge l'OCR ? » et recevez des réponses extraites directement des documents officiels—sans avoir besoin de quitter le chat ou de naviguer sur le site Web. Cela réduit considérablement les difficultés liées à l'assistance et permet l'intégration en temps réel et en libre-service pour les nouveaux utilisateurs.

4. Assistants de recherche et d'analyse des données :
Que vous travailliez dans le milieu universitaire ou dans le monde des affaires, vous pouvez disposer de rapports ou de fiches techniques PDF volumineux. Un chatbot RAG peut être configuré pour agir en tant qu'assistant de recherche, par exemple en extrayant des informations dans des rapports financiers, en résumant des livres blancs techniques ou en répondant à des questions à partir de PDF de recherche médicale. Ce cas d'utilisation recoupe le précédent : l'idée principale est de tirer parti de vos documents propriétaires comme base de connaissances pour un assistant d'IA.
Ce ne sont là que quelques scénarios ; pratiquement tous les domaines où des informations critiques sont verrouillées dans des PDF ou des fichiers texte peuvent bénéficier d'un système de discussion basé sur RAG. Par ancrer les réponses LLM dans vos données, vous obtenez un chatbot à la fois conversationnel et adapté à votre contenu.
Tutoriel étape par étape (basé sur une API)
Dans ce didacticiel, nous allons créer un projet RAG sur Eden AI, indexer un PDF et créer un chatbot capable de répondre aux questions de ce PDF. Nous soulignerons comment chaque étape correspond au flux RAG (indexation, récupération, génération).
Présentation de la configuration
Pour implémenter cela, nous allons utiliser Eden AI, une plateforme qui fournit une API unifiée pour divers services d'IA (LLM, intégrations, analyse d'images, etc.). Eden AI simplifie le levage des charges lourdes nécessaires à RAG en proposant tous les composants en un seul endroit :
- Base de données vectorielle gérée : Vous n'avez pas besoin de configurer vos propres serveurs de base de données vectorielles. Eden AI propose des options intégrées (comme Qdrant ou Supabase) pour stocker vos intégrations, ou vous pouvez connecter votre propre base de données si vous le souhaitez. Cette boutique gérée contiendra les vecteurs indexés de votre contenu PDF.
- Orchestration du modèle : Avec Eden, vous avez accès à de nombreux Fournisseurs d'IA via une seule clé API. Par exemple, vous pouvez utiliser OpenAI des modèles pour l'intégration et GPT-4 pour le LLM, ou passez à d'autres fournisseurs (Cohère, etc.) avec un changement de configuration. Eden AI gère les appels d'API à ces fournisseurs en coulisse, de sorte que vous n'interagissez qu'avec l'API unifiée d'Eden. Pas besoin de jongler avec plusieurs clés d'API ou SDK — une seule plateforme s'en charge.
- API et SDK unifiés : Toutes les opérations (indexer des données, poser des questions) sont exposées sous forme de simples points de terminaison REST ou via SDK d'Eden. Cela signifie que vous pouvez facilement intégrer le chatbot RAG à votre application ou à votre flux de travail à l'aide de requêtes HTTP standard. Les IA d'Eden portail fournit également une interface Web pour configurer et tester votre pipeline RAG sans écrire de code.
Pour plus de détails sur la mise en œuvre, vous pouvez consulter le Documentation sur l'IA d'Eden, qui inclut des guides, des références d'API et des exemples de SDK.
Vous pouvez également suivre ce didacticiel vidéo étape par étape sur YouTube, qui décrit l'ensemble du processus de configuration d'un chatbot RAG avec Eden AI.
Étape 1 : Inscrivez-vous sur Eden AI et obtenez une clé API
Phase RAG : (Configuration) — Avant que l'indexation ou la récupération puissent avoir lieu, vous devez accéder à la plateforme.
Tout d'abord, créez un compte Eden AI si ce n'est pas déjà fait. Accédez au Page d'inscription à Eden AI et inscrivez-vous. Une fois connecté, vous pouvez retrouver votre Clé API sur le tableau de bord (recherchez la section « Clé API », il s'agit d'une longue chaîne de caractères). Copiez cette clé ; nous l'utiliserons pour les appels d'API.

Remarque: La clé API est utilisée dans un en-tête HTTP pour authentifier vos requêtes. Eden AI utilise un système de jetons Bearer. Par exemple, vous allez inclure Authorization : Bearer YOUR_API_KEY dans vos appels REST. Gardez votre clé API secrète (traitez-la comme un mot de passe).
Étape 2 : Création d'un projet RAG (configuration des modèles et de la base de données vectorielles)
Phase RAG : (Configuration et configuration) — C'est ici que nous configurons le fonctionnement de l'indexation et de la génération en choisissant les modèles et la base de données.
La plateforme Eden AI vous permet de le faire via une interface Web (soit un modèle de démarrage rapide, soit une configuration manuelle), mais ici, nous utiliserons également du code Python pour démontrer le processus via une API.
À l'aide de l'interface utilisateur Web d'Eden :
Sur le tableau de bord Eden AI, accédez au Chatbot personnalisé (RAG) section et créez un nouveau projet. Vous serez invité à renseigner certains paramètres pour votre pipeline RAG :
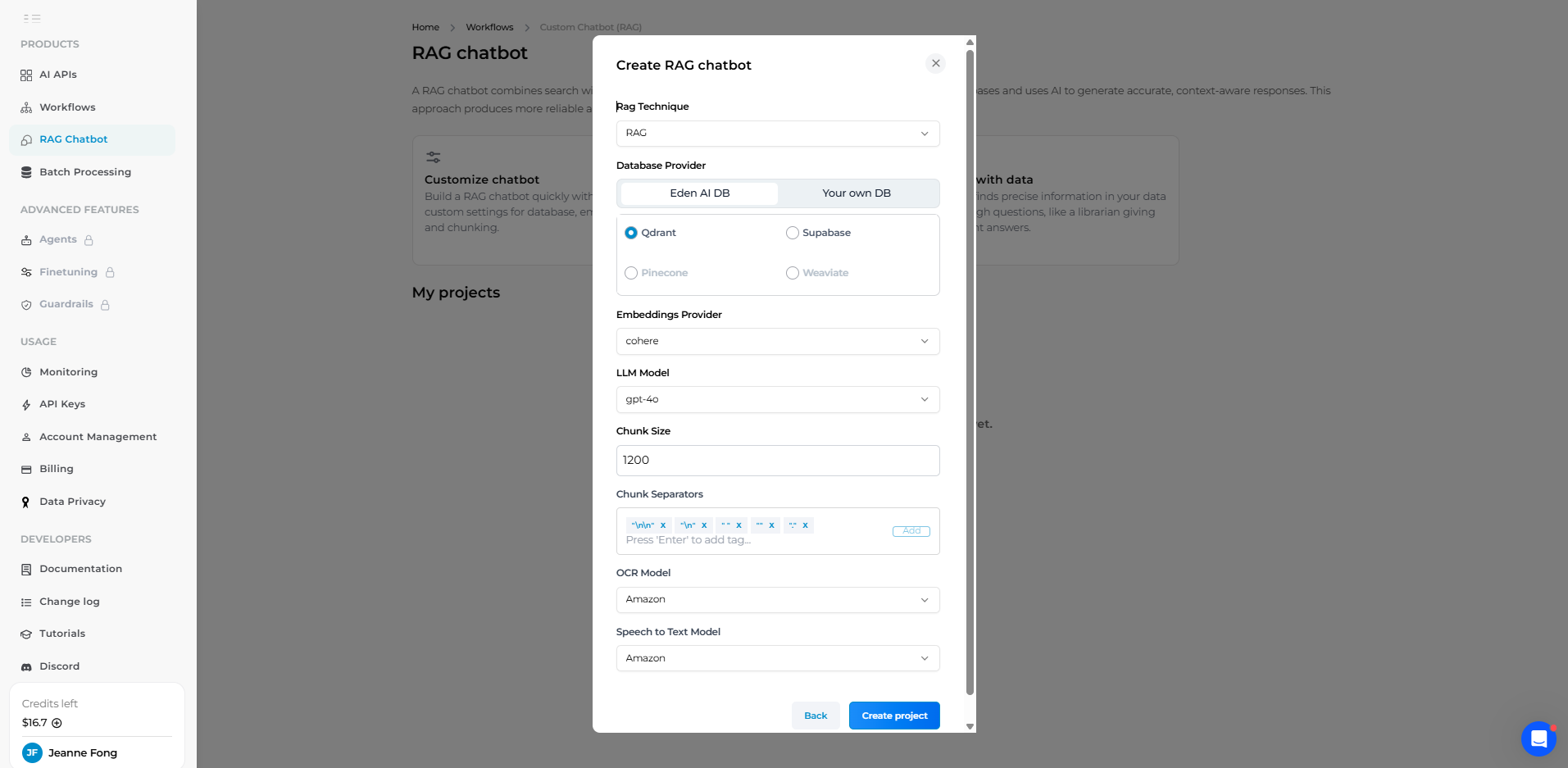
- Nom du projet : Donnez un nom à votre projet (par exemple, « PDF Chatbot Demo »). C'est juste pour votre référence. La plateforme Eden créera un ID du projet pour vous : notez cet identifiant car il sera utilisé dans les points de terminaison de l'API pour faire référence à votre projet RAG.
- Base de données vectorielles : Sélectionnez une base de données vectorielle pour stocker vos intégrations. Eden AI propose des options telles que Base de données ou Qdrant sorti de la boîte. Dans la plupart des cas d'utilisation, vous pouvez choisir le Qdrant (un magasin vectoriel haute performance) fourni par Eden afin de ne pas avoir besoin de configuration externe. (Si vous gérez déjà une base de données vectorielle, Eden permet de saisir une URL et une clé personnalisées, mais nous nous en tiendrons à l'option gérée pour des raisons de simplicité.)
- Fournisseur d'intégrations : Choisissez le modèle à utiliser pour générer des intégrations à partir du texte de votre document. Un choix courant est L'intégration de texte ada-002 d'OpenAI modèle, qu'Eden AI peut utiliser si vous sélectionnez OpenAI comme fournisseur. (Vous pouvez également choisir des alternatives telles que Cohere, Mistral, OpenAI, Google, Jina, etc.) Le modèle d'intégration convertit des morceaux de texte en forme vectorielle ; l'utilisation d'un modèle de haute qualité améliore la précision de la récupération.
- LLM (modèle de chat) : Choisissez un grand modèle linguistique pour générer des réponses. Dans notre cas, nous voulons un chatbot doté de fortes capacités, donc OpenAI GPT-4 est un bon choix. Eden AI vous permet de choisir parmi plusieurs LLM (GPT-3.5, GPT-4, Claude, etc., selon la disponibilité). Dans cet exemple, nous utiliserons GPT-4 pour nous assurer que notre chatbot peut traiter des requêtes complexes. Ce modèle sera utilisé dans la phase de génération pour produire des réponses à partir des informations récupérées.
- Taille du morceau : Définissez la taille des blocs (en caractères ou en jetons) pour le fractionnement des documents. L'interface d'Eden AI peut utiliser par défaut quelque chose comme 1200 jetons. Cela détermine la taille de chaque bloc de texte lors de l'indexation de PDF. Une taille de bloc plus grande signifie moins de morceaux (moins de frais généraux), mais chaque bloc utilise davantage la fenêtre contextuelle du LLM ; une taille de bloc plus petite signifie des éléments plus granulaires qui peuvent correspondre plus précisément aux requêtes. Une fourchette typique est de 500 à 1 000 jetons ; 1 200 est raisonnable pour le vaste contexte de GPT-4.
- Séparateurs de morceaux : Définissez la manière dont le texte du document est scindé. Par défaut, Eden AI se divise en fonction de limites telles que des phrases (points).
.), de nouvelles lignes ou de nouveaux paragraphes. Vous pouvez généralement laisser cette valeur par défaut, ce qui signifie que le texte du PDF sera découpé aux points d'arrêt naturels (fin de phrases ou de paragraphes). Cela garantit la cohérence sémantique des morceaux. - OCR et synthèse vocale (facultatif) : Si vous envisagez de télécharger des images ou du son, Eden AI vous permet de configurer un modèle d'OCR (pour extraire du texte à partir d'images/de numérisations PDF) et un modèle de synthèse vocale (pour les fichiers audio). Par exemple, vous pouvez choisir Mistral pour l'OCR si vos PDF sont numérisés, et peut-être OpenAI Whisper ou AssemblyAI pour la synthèse vocale. Pour les PDF en texte pur, ils ne sont pas nécessaires.
Une fois que vous avez renseigné ces paramètres, cliquez sur « Créer un projet ». Eden AI lancera le projet avec les modèles choisis et la base de données vectorielles. Dans l'interface utilisateur, vous verrez maintenant votre nouvelle interface de projet RAG.
À l'aide de l'API :
Maintenant, créons un projet en utilisant IA ouverte en tant que fournisseur d'intégration et de LLM (par exemple, en utilisant intégration de texte ada-002 modélisez les coulisses pour les intégrations et GPT-4 pour répondre). Nous utiliserons la base de données Qdrant gérée par défaut par Eden AI. En Python, vous pouvez utiliser demandes bibliothèque pour appeler l'API REST d'Eden AI :
Une fois exécutée, cela créera un nouveau projet RAG sur Eden AI. La réponse (project_info) contiendra les détails du projet, y compris un project_id unique (un UUID) qui identifie votre base de connaissances et votre configuration. N'oubliez pas de noter ce project_id, nous l'utiliserons lors des prochains appels d'API.
ÉMOJIS
Félicitations, vous avez créé la fondation ! À ce stade, vous avez un chatbot vide sans aucune donnée. Ensuite, nous allons indexez votre PDF.
Étape 3 : Télécharger des fichiers PDF (indexation)
Phase RAG : (Indexation) — Nous introduisons maintenant des documents dans le système, qui seront intégrés et stockés dans la base de données vectorielles.
Une fois le projet RAG créé, vous pouvez y ajouter des données. Eden AI prend en charge plusieurs formats de données : vous pouvez coller du texte brut ou télécharger des fichiers tels que PDF, audio (mp3), CSV et même des URL de pages Web. Pour notre cas d'utilisation, nous téléchargerons un ou plusieurs fichiers PDF.

À l'aide de l'interface utilisateur Web d'Eden :
Dans l'interface du projet, recherchez Données section où vous pouvez télécharger des documents. Il vous suffit de glisser-déposer votre PDF ou de cliquer pour le télécharger. La plateforme gérera automatiquement l'extraction du texte du PDF, son découpage et la création d'intégrations pour chaque bloc.
Par exemple, si vous aviez une liste de contacts au format PDF (comme dans notre test), vous la téléchargez et vous attendez un moment pour le traitement. Une fois chargé, Eden AI indiquera que le contenu du document a été indexé (vous pouvez souvent voir le nombre de morceaux stockés).
À l'aide de l'API :
Vous pouvez également ajouter des documents via un appel d'API REST. Eden AI fournit un point de terminaison pour télécharger un fichier dans votre projet RAG. Voici comment vous pouvez le faire en Python (en utilisant le demandes bibliothèque) :
Ce ajouter_fichier L'appel d'API envoie le fichier PDF à Eden AI. Le service traitera le fichier comme le fait l'interface utilisateur : en le divisant en morceaux et en générant des intégrations à stocker dans la base de données vectorielles.
Si la demande aboutit, vous devriez obtenir un code d'état 200 et éventuellement une réponse JSON confirmant le téléchargement. (Vous pouvez également télécharger plusieurs PDF. Il suffit de répéter cette étape pour chaque fichier. Eden combinera tous leurs morceaux dans le même indice vectoriel.)
À ce stade, nous avons a indexé le PDF contenu. Sous le capot, chaque partie de votre PDF est désormais représentée sous forme de vecteur et stockée dans la base de données du projet. Nous sommes prêts à poser des questions !
Vous pouvez répéter cette étape pour tous vos documents, par exemple en chargeant plusieurs PDF ou en mélangeant du texte et des URL. Eden AI maintiendra un collection de tous ces éléments pour constituer la base de connaissances de votre chatbot.
Remarque : Si vous utilisez le portail Web Eden AI, vous pouvez gérer et inspecter les segments dans l'interface utilisateur (afficher le contenu des segments, supprimer les segments indésirables, etc.), mais via l'API, cette gestion peut être effectuée avec des points de terminaison pour supprimer ou interroger des segments si nécessaire.
Étape 4 : définir une invite système (personnaliser la génération)
Phase RAG : (Configuration de la génération) — Cette étape est facultative mais recommandée pour guider le comportement du LLM lorsqu'il répond.
UNE invite du système est comme une instruction ou un personnage donné au modèle linguistique du chatbot. Cela permet de définir comment le bot doit réagir.
À l'aide de l'interface utilisateur Web d'Eden :
Par exemple, vous souhaiterez peut-être que le bot réponde de manière officielle, qu'il cite toujours la source ou qu'il joue un certain rôle (comme « agir en tant que tuteur utile »). Dans l'interface d'Eden AI, vous trouverez une section pour Invite du système pour votre bot.
Dans notre cas, définissons l'invite du système en fonction d'un assistant technique qui répondra aux questions concernant nos PDF.
Par exemple, si nos PDF sont des manuels techniques, nous pouvons définir une invite telle que :

Une fois enregistré et activé, cette invite système sera appliquée au LLM à chaque requête. Essentiellement, Eden AI ajoutera ces instructions à la conversation afin que le LLM sache comment se comporter.
À l'aide de l'API :Vous pouvez définir l'invite du système via l'API en appelant le profil bot point de terminaison avec une charge utile JSON contenant le texte de votre invite. (Il existe également un nom pour le profil et un modèle champ qui doit généralement correspondre au LLM que vous avez choisi, par exemple, « gpt-4 ».)
Voici un exemple d'appel d'API :
Pour des raisons de simplicité, vous pouvez également ignorer cette étape. Eden AI utilisera une invite système par défaut si vous n'en fournissez pas. Cependant, il est fortement recommandé de créer une bonne invite système pour s'assurer que le chatbot répond de la manière souhaitée (ton, contexte et limites corrects).
Étape 5 : Testez votre chatbot RAG via l'interface utilisateur (récupération + génération)
Phase RAG : récupération et génération — Maintenant que votre contenu d'intégration est indexé et que votre LLM est configuré, il est temps de tester votre chatbot pour vous assurer qu'il renvoie des réponses pertinentes et fondées.
Accédez à la section Chat de votre projet RAG. Vous trouverez une interface de chat en direct similaire à ChatGPT où vous pouvez saisir une requête utilisateur et observer la réponse du modèle. Assurez-vous que le LLM correct est sélectionné (par exemple GPT-4 tel que configuré à l'étape 2) et que votre manuel d'intégration a été entièrement traité et indexé.
Essayons une question pratique basée sur le PDF indexé :

Une fois soumis, Eden AI va :
- Convertissez la requête en intégration
- Effectuez une recherche de similarité dans la base de données vectorielles pour récupérer les éléments les plus pertinents du PDF d'intégration
- Combinez la requête et les morceaux récupérés dans une invite
- Envoyer l'invite au LLM
- Renvoie une réponse générée
Lors de notre test, la réponse est basée sur le document d'intégration, citant directement la section de configuration du développement que nous avons incluse. Si l'invite de votre système est configurée (par exemple, « Agissez en tant qu'assistant interne ». Donnez toujours des réponses concises, étape par étape, aux questions d'intégration. »), vous remarquerez que le ton et le format correspondent à votre intention.
💡 Vous pouvez vérifier quelles données ont été utilisées pour générer la réponse en cliquant sur l'onglet « Database Chunks ». Cela vous indique exactement quelles parties du PDF d'intégration ont été récupérées. Par exemple, l'assistant a peut-être extrait deux morceaux :
- Un expliquant le processus de configuration
- Un autre détaillant les variables d'environnement

Cette transparence facilite le débogage et l'amélioration des résultats. Si l'assistant renvoie des réponses hors sujet ou des réponses incomplètes, vous pouvez ajuster la taille du bloc, modifier le contenu source ou affiner votre invite.
À ce stade, vous avez créé votre propre assistant de discussion interne à l'aide de RAG, le tout sans écrire de logique de base de données vectorielle ni de wrappers LLM.
Étape 6 : Intégrez l'API RAG dans votre application (récupération + génération)
Phase RAG : (Récupération et génération via API) — Enfin, pour utiliser ce chatbot dans votre propre application (application web, bot Slack, etc.), vous allez appeler l'API d'Eden AI depuis votre code.
Lors d'une interaction classique, vous devez effectuer deux appels d'API principaux : l'un pour ajouter des documents (que nous avons abordé à l'étape 3 avec add_file) et l'autre pour poser des questions. Comme nous avons déjà téléchargé le PDF, nous pouvons passer directement à la requête.
Eden AI fournit un point de terminaison `/ask_llm` pour les requêtes RAG, qui gère les récupérer et générer opération sur le backend.
Essentiellement, cet appel d'API unique répondra à une question de l'utilisateur, trouvera des segments de document pertinents dans le magasin vectoriel et renverra une réponse depuis le LLM.
Voici un exemple simplifié en Python utilisant des requêtes pour poser une question :
Dans la charge utile :
- `query` est la question de l'utilisateur.
- llm_provider et llm_model spécifient le LLM à utiliser pour la génération (cela doit correspondre à ce que vous avez défini dans le projet ; Eden AI autorise le remplacement, mais en général, vous utiliserez celui configuré).
- `k` est le nombre de morceaux à récupérer dans la base de données vectorielle (ici 3, qui est une valeur par défaut courante). L'API renverra une réponse basée sur ces k premiers segments pertinents.
La réponse contient généralement le texte de la réponse et peut également inclure les documents récupérés ou d'autres métadonnées en fonction du format de l'API d'Eden. Par exemple, vous pourriez obtenir un JSON avec la réponse et peut-être des références aux ID de bloc utilisés. Vous pouvez mettre en forme ou afficher la réponse selon vos besoins dans l'interface utilisateur de votre application.
Vous avez maintenant le pouvoir de votre Chat basé sur des balises avec des fichiers PDF accessible via une API. Vous pouvez l'intégrer dans une interface Web : par exemple, créer une boîte de discussion dans votre application où une question d'utilisateur déclenche une demande à votre backend, qui appelle ensuite Eden's /demande_llm point de terminaison et renvoie la réponse à afficher. De cette façon, les tâches NLP lourdes sont gérées par le backend géré d'Eden AI.
Un bref résumé de ce que fait l'API Eden AI ici : lorsque vous appelez /demande_llm, Eden reçoit votre requête et sait quel projet (et donc quelle base de données vectorielle et quels documents) utiliser par {id_projet} dans l'URL. Il effectue ensuite la recherche de similarité dans la base de données vectorielles pour obtenir les segments de document pertinents, et les transmet au LLM (GPT-4) avec l'invite du système et la requête de l'utilisateur, générant une réponse finale.
Tout cela est résumé dans un seul appel d'API effectué par votre application. C'est assez puissant : vous n'avez pas eu à configurer un serveur de base de données vectorielles, à écrire du code d'intégration ou à trouver comment appeler un LLM avec contexte ; Eden AI l'orchestre.
Une fois l'intégration en place, votre application dispose désormais essentiellement d'une fonctionnalité « ChatGPT, mais avec mes PDF ». Le chatbot fera toujours référence au contenu PDF que vous avez fourni pour répondre à des questions, ce qui le rend très spécifique à vos données et utile pour vos utilisateurs ou votre équipe.
Étape 7 : Intégrez le chatbot à votre site Web (intégration optionnelle de l'interface utilisateur)
Phase RAG : déploiement complet du système — Une fois que votre chatbot est fonctionnel via l'API ou l'interface utilisateur Eden, vous pouvez le rendre accessible aux utilisateurs finaux en l'intégrant directement à votre site Web ou à votre application.
Eden AI fournit un script d'intégration prêt à l'emploi qui fonctionne immédiatement. Collez simplement l'extrait de code suivant dans le code HTML de votre site, dans le <body> étiquette :
✅ N'oubliez pas de remplacer {project_id} par votre identifiant de projet Eden AI actuel.
Ce script va automatiquement :
- Chargez l'interface utilisateur du chatbot sur votre site,
- Connectez-le à votre projet RAG,
- Utilisez le fournisseur LLM configuré (par exemple OpenAI GPT-4),
- Et permettez aux utilisateurs de poser des questions en temps réel.
Vous pouvez placer ce widget n'importe où : dans le tableau de bord d'un produit, sur un portail de documentation interne ou même sur une page de support client. C'est l'idéal si vous souhaitez déployer votre chatbot RAG avec aucun codage frontal.
Si vous souhaitez une personnalisation complète de l'interface utilisateur, vous pouvez également créer votre propre interface et appeler l'API RAG d'Eden AI (/demande_llm) directement.
Conclusion
La génération augmentée par extraction vous permet de discutez avec vos PDF de manière vraiment efficace, en comblant le fossé entre les données brutes et les questions-réponses intelligentes. En indexant vos documents dans une base de données vectorielle et en tirant parti d'un LLM pour les réponses en langage naturel, vous obtenez le meilleur des deux mondes : des informations pertinentes et à jour avec la maîtrise d'un grand modèle linguistique.
Dans ce didacticiel, nous avons parcouru l'intégralité du flux RAG : chargement et fractionnement d'un PDF, intégration et stockage (indexation), récupération en temps réel du texte pertinent et génération de réponses par un LLM. Nous avons également montré comment l'API unifiée d'Eden AI simplifie considérablement ce processus pour les développeurs.
Les avantages d'Eden AI sont clairs : il gère l'infrastructure (stockage vectoriel, intégration de modèles, OCR, etc.) et propose une API et une interface propres pour la gérer. Cela signifie que vous pouvez vous concentrer sur le développement de l'expérience utilisateur (qu'il s'agisse d'un outil interne, d'un chatbot orienté client ou d'une fonctionnalité de votre SaaS) plutôt que de regrouper les composants de l'IA. Avec un support intégré pour plusieurs fournisseurs et un généreux niveau gratuit pour commencer, l'essayer est facile.
C'est maintenant à votre tour : rassemblez quelques documents PDF (manuels d'utilisation, documents politiques, documents de recherche, tout ce que vous voulez que votre chatbot apprenne) et essayez Eden AI. En quelques étapes seulement, vous pouvez créer un Chat basé sur des balises avec des fichiers PDF opérationnel. Nous vous encourageons à essayer les instructions du système et les différents paramètres du modèle pour adapter le comportement du bot. Avec RAG, »parler à vos documents» n'est pas de la science-fiction, c'est une fonctionnalité pratique que vous pouvez mettre en œuvre dès aujourd'hui. Alors allez-y et commencez à créer votre propre chatbot PDF avec Eden AI, et tirez pleinement parti de vos documents !
Bon codage ! 🗒️🤖✨


.jpeg)
.jpeg)