
Résumez cet article avec :
- Claude Opus 4.8 est désormais disponible sur Eden AI via l’API unifiée, avec le model ID
claude-opus-4-8. - Il améliore les performances d’Opus 4.7 en agentic coding, avec 69,2 % contre 64,3 %, et est 4x moins susceptible de manquer des erreurs dans son propre code généré.
- Le modèle est conçu pour les workflows complexes, comme les migrations de codebase, l’analyse de documents juridiques, la synthèse de recherche et les tâches de knowledge work en entreprise.
- Sa fenêtre de contexte de 1M de tokens permet de traiter des codebases complètes, des contrats, des dossiers juridiques ou des corpus de recherche en un seul appel, sans découpage.
- Eden AI permet aux développeurs de tester Claude Opus 4.8, de le comparer à des modèles plus légers, et de changer de modèle avec un simple paramètre, sans réécrire leur intégration.
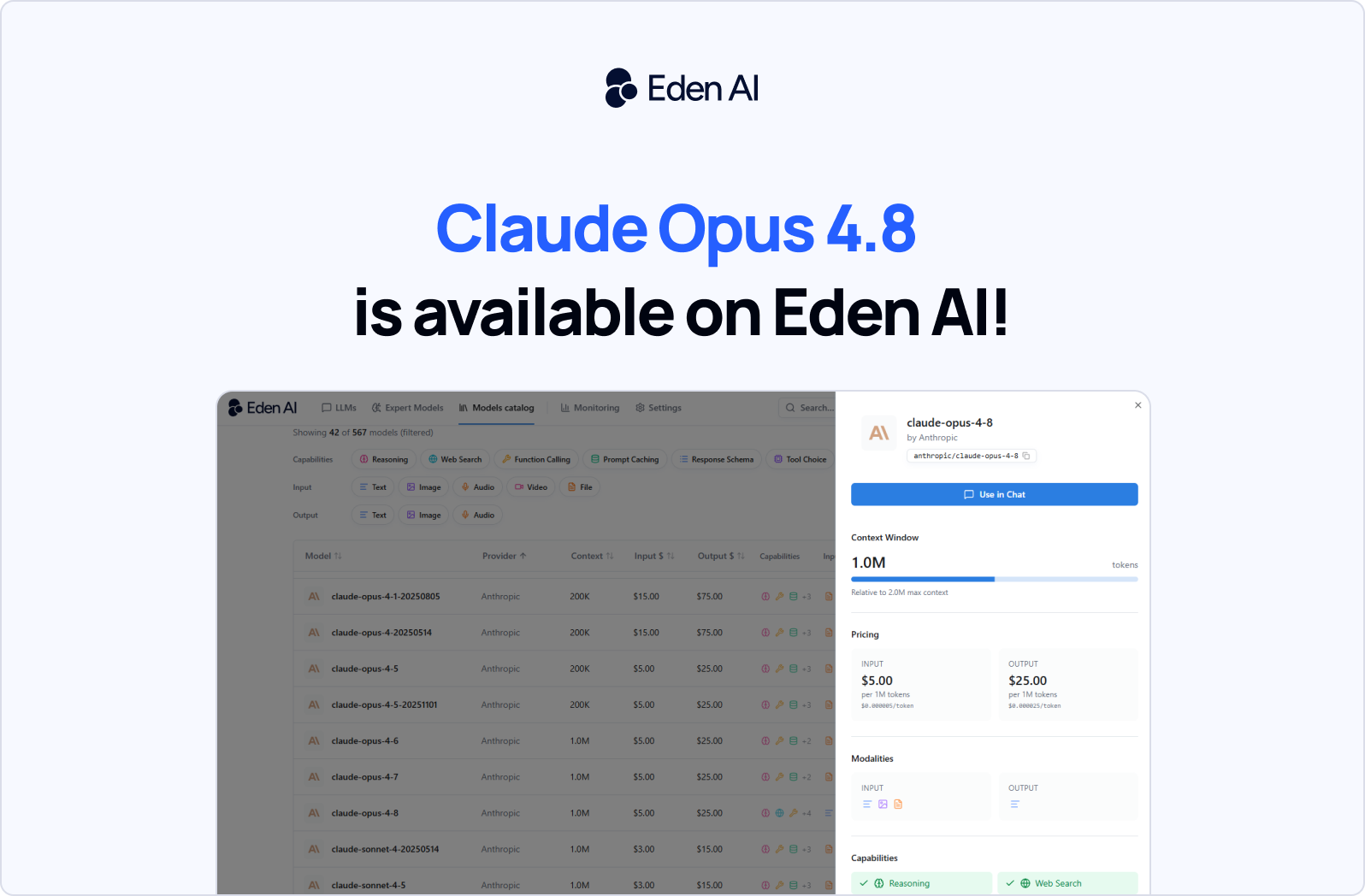
Claude Opus 4.8 est le dernier modèle Opus d’Anthropic, lancé le 28 mai 2026, et désormais disponible via l’API unifiée d’Eden AI sous l’identifiant de modèle claude-opus-4-8.
Il conserve le même tarif qu’Opus 4.7, soit 5 $ par million de tokens en entrée et 25 $ par million de tokens en sortie, tout en améliorant la qualité de jugement pour des tâches comme la revue de code, les décisions nécessitant un raisonnement avancé et les workflows IA dynamiques.
Pour les développeurs qui utilisent déjà Opus 4.7, l’intérêt principal est de bénéficier d’un modèle plus fiable pour évaluer les résultats, détecter les problèmes et s’adapter à des parcours d’exécution complexes.
Voici un aperçu de sa comparaison avec son prédécesseur.
Nouveautés de Claude Opus 4.8
Revue de code plus précise
Claude Opus 4.8 est conçu pour être plus fiable lors de la revue de code, qu’il s’agisse de code généré par l’IA ou écrit par des développeurs. Par rapport à Opus 4.7, il est 4 fois moins susceptible de manquer des erreurs dans son propre code généré, ce qui le rend particulièrement utile pour le debugging, la refactorisation et les workflows de revue de code automatisée.
Le modèle se montre également plus transparent sur ses incertitudes, ce qui aide les développeurs à distinguer les recommandations fiables des points qui nécessitent une validation supplémentaire.
Workflows dynamiques
Claude Opus 4.8 améliore la prise en charge des workflows agentiques complexes, impliquant de nombreuses étapes et plusieurs composants. Il peut orchestrer des dizaines, voire des centaines de sous-agents en parallèle, générer ses propres scripts d’orchestration et coordonner les résultats à travers plusieurs chemins d’exécution.
Il peut aussi vérifier ou réfuter des conclusions intermédiaires, reprendre des tâches interrompues et accompagner des migrations à l’échelle d’une base de code, lorsque le contexte long et le suivi structuré sont essentiels.
Contrôle de l’effort
Claude Opus 4.8 introduit un nouveau paramètre permettant de mieux gérer l’équilibre entre vitesse, profondeur de raisonnement et coût pour chaque requête. Les développeurs peuvent ajuster le niveau d’effort du modèle selon la tâche : des réglages plus légers pour les opérations courantes, et des réglages plus approfondis pour les analyses complexes ou les raisonnements en plusieurs étapes.
Cela donne aux équipes enterprise davantage de contrôle sur la latence et le budget, sans avoir à changer de modèle pour chaque type de workload.
Fast Mode
Le Fast Mode est pensé pour les cas d’usage où la faible latence est plus importante que la profondeur maximale de raisonnement. Il peut fonctionner jusqu’à 2,5 fois plus rapidement et coûte 10 $ par million de tokens en entrée et 50 $ par million de tokens en sortie.
Ce mode est particulièrement utile pour les outils de développement interactifs, les boucles d’agents IA et les workflows de production où la réactivité est une priorité.
Messages système en cours de conversation
Claude Opus 4.8 permet désormais d’insérer des messages système en cours de tâche, directement dans le tableau messages. Les développeurs peuvent ainsi mettre à jour les instructions pendant des workflows longs, sans casser le cache de prompt.
Pour les exécutions agentiques en plusieurs étapes, cela peut réduire les coûts tout en facilitant l’ajustement du comportement du modèle à mesure que les besoins évoluent.
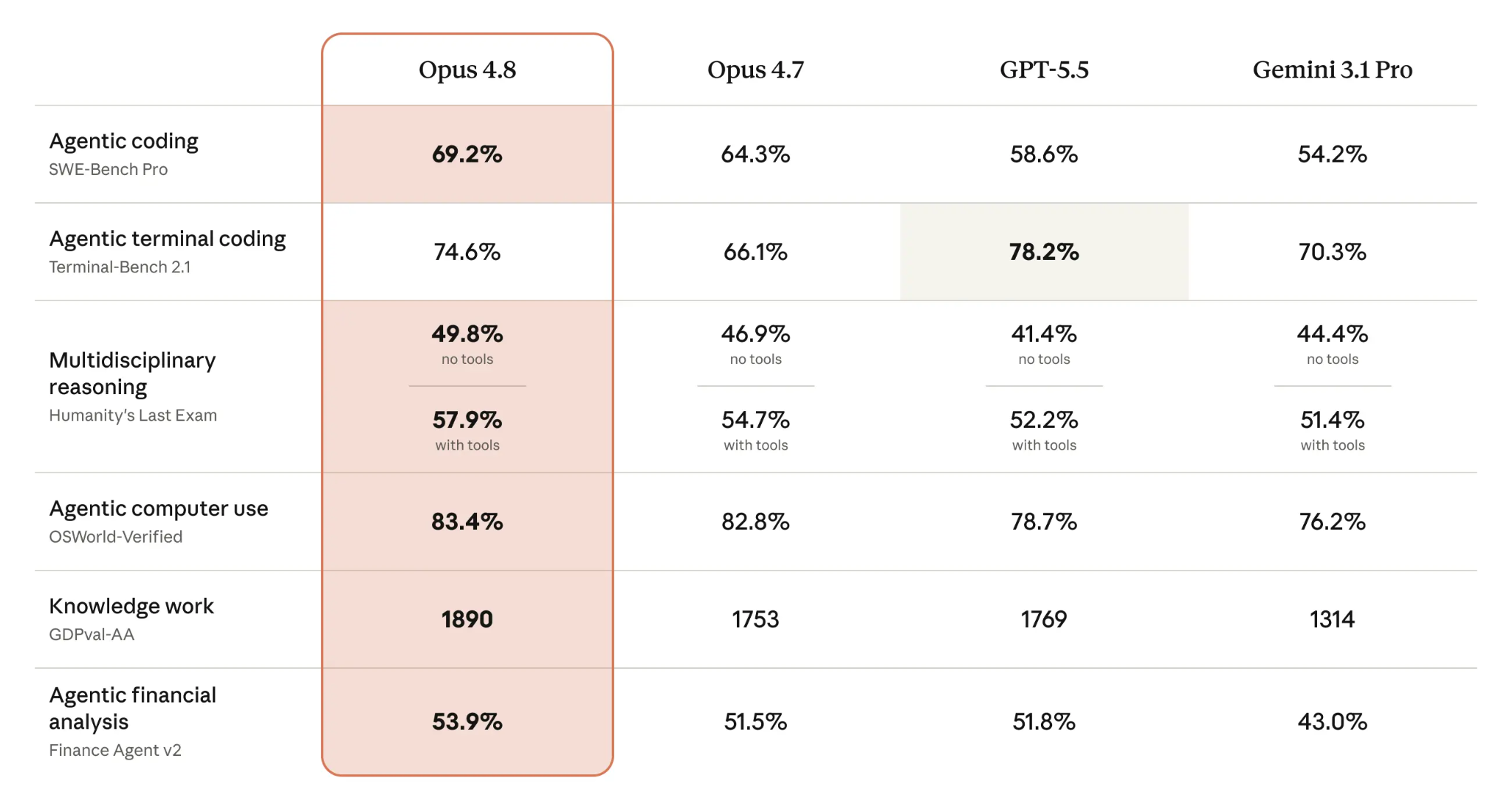
Résultats des benchmarks : Opus 4.8 vs Opus 4.7
Les benchmarks sont utiles lorsqu’ils aident à prendre de meilleures décisions en production : fiabilité du modèle, taux de complétion, latence et coût par tâche réussie. Pour les développeurs et les équipes IA, la vraie question n’est donc pas seulement de savoir si Claude Opus 4.8 obtient de meilleurs scores qu’Opus 4.7, mais s’il permet de finaliser davantage de workflows réels avec moins de tentatives et moins d’intervention manuelle.
Le résultat le plus important concerne le benchmark Super-Agent : Claude Opus 4.8 est le seul modèle à avoir complété tous les cas de bout en bout. Il surpasse les précédents modèles Opus sur la complétion de tâches complètes et égale GPT-5.5 en performance ajustée au coût, ce qui en fait une option solide pour les workflows agentiques en production, lorsque la fiabilité et l’efficacité sont toutes deux essentielles.
Meilleurs cas d’usage de Claude Opus 4.8
Agentic coding et développement logiciel
Claude Opus 4.8 offre une base plus solide pour l’ingénierie logicielle assistée par IA. Il se classe n°1 sur le benchmark d’agentic coding avec 69,2 %, contre 64,3 % pour Opus 4.7, ce qui montre de meilleures performances sur les tâches de code complexes nécessitant planification, exécution et validation.
Cette progression est particulièrement pertinente pour la revue de code. Claude Opus 4.8 est 4 fois moins susceptible de manquer des erreurs dans son propre code généré, ce qui aide à réduire les angles morts lors de l’utilisation d’agents IA pour le debugging, la refactorisation ou la revue de code de production.
Pour les équipes SaaS B2B, cela le rend particulièrement utile pour les migrations de bases de code, les refactorisations multi-fichiers, les mises à jour de dépendances et le debugging en production, lorsque le contexte et la fiabilité sont déterminants.
Workflows d’agents IA dynamiques
Claude Opus 4.8 est conçu pour les agents IA qui doivent gérer des tâches complexes, et pas seulement répondre à un prompt isolé. Il peut planifier le travail, appeler des outils, exécuter des sous-agents en parallèle, vérifier leurs résultats et transformer la sortie finale en rapport structuré.
Cela le rend utile pour des workflows comme les agents de recherche, les agents de code, les copilotes internes ou les assistants opérationnels. Un flux typique peut par exemple consister à planifier la tâche, utiliser les bons outils, vérifier les résultats, puis résumer ce qui a été fait.
Pour les AI builders et les équipes produit, l’avantage principal est la continuité. Claude Opus 4.8 peut conserver le contexte et le style rédactionnel sur des tâches longues et multi-sessions, ce qui aide les agents à rester cohérents dans le temps.
Analyse juridique et documentaire
Claude Opus 4.8 est particulièrement adapté aux workflows juridiques et conformité, où l’exactitude, la traçabilité et le raisonnement rigoureux sont essentiels. Il a obtenu le meilleur score jamais enregistré sur le Legal Agent Benchmark et est devenu le premier modèle à dépasser les 10 % en all-pass, ce qui montre des progrès sur des tâches juridiques complexes qui nécessitent une complétion de bout en bout, plutôt que des réponses isolées.
Grâce à sa fenêtre de contexte de 1 million de tokens, les équipes peuvent traiter des dossiers complets, contrats, politiques internes ou documents réglementaires dans un seul appel, ce qui réduit le besoin de découper les documents en plusieurs prompts. Autre point important : Claude Opus 4.8 est conçu pour signaler ses incertitudes plutôt que d’inventer une réponse, un élément essentiel pour les cas d’usage sensibles où les hallucinations peuvent créer un risque juridique, financier ou réglementaire.
Recherche et synthèse de connaissances
Claude Opus 4.8 est bien adapté aux workflows de recherche et de synthèse de connaissances qui exigent une comparaison rigoureuse entre de nombreuses sources. Il peut résumer des articles, comparer des arguments opposés, extraire des méthodologies et relier des résultats entre plusieurs documents, sans réduire l’analyse à un simple résumé superficiel.
Pour les analystes, chercheurs et équipes stratégie, cela le rend utile pour les rapports financiers, les études de marché, les articles techniques et les bases de connaissances internes, lorsque les détails comptent. Avec sa fenêtre de contexte de 1 million de tokens, les équipes peuvent fournir un corpus complet en un seul appel, au lieu de diviser les documents en petits morceaux, ce qui aide à préserver le contexte, la structure et les relations entre les sources tout au long de l’analyse.
Travail de connaissance en entreprise
Claude Opus 4.8 est conçu pour les tâches de knowledge work en entreprise, qui s’étendent souvent sur plusieurs outils, fichiers et cycles de décision. Il peut gérer des projets complexes sur plusieurs jours, de l’analyse initiale jusqu’aux recommandations structurées, sans perdre le contexte en cours de route.
Pour les responsables opérations, les AI product managers et les acheteurs enterprise, cela est particulièrement utile sur des supports comme les spreadsheets, les présentations et les documents métier nécessitant un rendu professionnel. Claude Opus 4.8 peut analyser les inputs, suivre des instructions détaillées et produire des livrables alignés avec les attentes business, des rapports internes aux synthèses prêtes pour le comité exécutif.
Ses progrès en suivi d’instructions et en cohérence de style le rendent aussi plus fiable sur les sessions longues, lorsque le ton, le format et les critères de décision doivent rester stables dans le temps.
Quand utiliser Claude Opus 4.8 plutôt que des modèles plus légers ?
Claude Opus 4.8 est particulièrement adapté aux tâches complexes, multi-étapes, sensibles ou nécessitant un long contexte, lorsque la qualité du raisonnement et la fiabilité comptent davantage que la vitesse brute. C’est un choix pertinent pour les workflows agentiques, l’analyse de bases de code, la revue juridique, la synthèse de recherche et le knowledge work en entreprise.
Pour des tâches plus simples comme la classification, les résumés courts, le routage ou l’extraction basique, des modèles plus rapides et moins coûteux comme Haiku ou Sonnet peuvent être plus adaptés.
Avec l’API unifiée d’Eden AI, les équipes peuvent passer de Claude Opus 4.8 à des modèles plus légers en modifiant un seul paramètre, sans réécrire leur intégration.
import requests
url = "https://api.edenai.run/v2/multimodal/chat"
headers = {
"Authorization": "Bearer YOUR_EDEN_AI_API_KEY",
"Content-Type": "application/json"
}
payload = {
"providers": ["claude-opus-4-8"],
"messages": [{"role": "user", "content": "Review this code for bugs and suggest improvements."}],
"max_tokens": 1024,
"temperature": 0
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())

.jpg)
.png)
%20(1).png)
