
Summarize this article with:
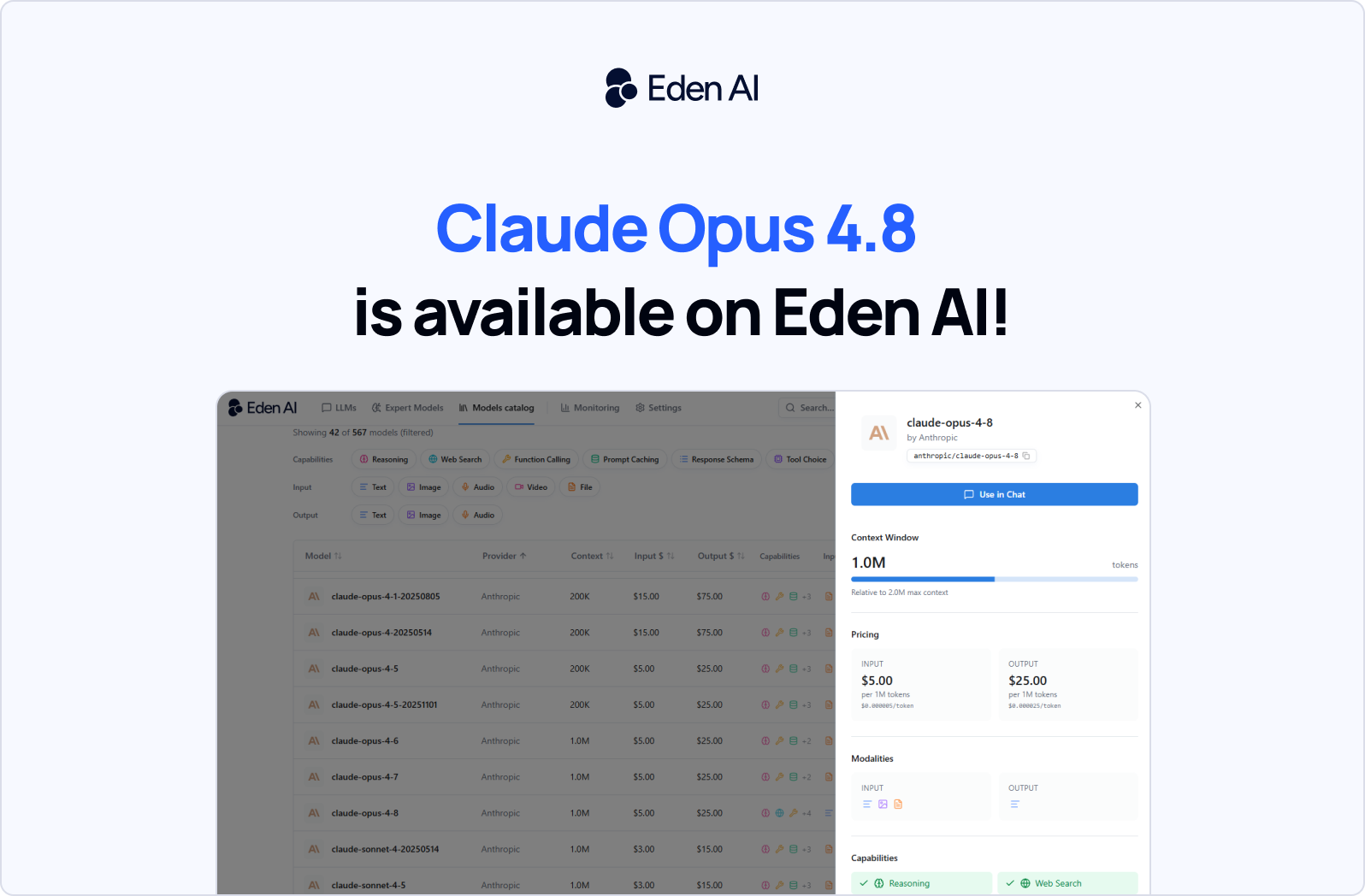
- Claude Opus 4.8 is now available on Eden AI through the unified API with the model ID
claude-opus-4-8. - It improves on Opus 4.7 for agentic coding, reaching 69.2% vs. 64.3%, and is 4x less likely to miss flaws in its own generated code.
- The model is built for complex workflows, including codebase migrations, legal document analysis, research synthesis, and enterprise knowledge work.
- Its 1M token context window helps teams process full codebases, contracts, case files, or research corpora in a single call without chunking.
- Eden AI lets developers test Claude Opus 4.8, compare it with lighter models, and switch models with a single parameter change, without rewriting their integration.
Claude Opus 4.8 is Anthropic’s latest Opus model, released on May 28, 2026, and now available through Eden AI’s unified API under the model ID claude-opus-4-8. It keeps the same pricing as Opus 4.7, at $5 per 1M input tokens and $25 per 1M output tokens, while improving judgment quality for tasks such as code review, reasoning-heavy decisions, and dynamic AI workflows.
For developers already using Opus 4.7, the main value is a more reliable model for evaluating outputs, catching issues, and adapting across complex execution paths. Here is how it compares to its predecessor at a glance.
What's New in Claude Opus 4.8
Sharper Code Review
Claude Opus 4.8 is designed to be more reliable when reviewing generated or human-written code. Compared with Opus 4.7, it is 4x less likely to miss flaws in its own generated code, which makes it more useful for debugging, refactoring, and automated review workflows. It is also more honest about uncertainty, helping developers distinguish between confident recommendations and areas that require further validation.
Dynamic Workflows
Claude Opus 4.8 improves support for complex agentic workflows that involve many moving parts. It can orchestrate tens to hundreds of parallel subagents, write its own orchestration scripts, and coordinate findings across multiple execution paths. It can also verify and refute intermediate conclusions, resume interrupted jobs, and support codebase-scale migrations where long-running context and structured follow-through matter.
Effort Controls
Claude Opus 4.8 introduces a new parameter for controlling the tradeoff between speed, reasoning depth, and cost on each request. Developers can tune the model’s effort level depending on the task, using lighter settings for routine operations and deeper settings for complex analysis or multi-step reasoning. This gives enterprise teams more control over latency and budget without needing to change models for every workload.
Fast Mode
Fast Mode is built for use cases where lower latency matters more than maximum reasoning depth. It runs up to 2.5x faster and is priced at $10 per 1M input tokens and $50 per 1M output tokens. This makes it useful for interactive coding tools, agent loops, and production workflows where responsiveness is a priority.
Mid-Conversation System Messages
Claude Opus 4.8 now supports inserting system messages mid-task directly inside the messages array. This allows developers to update instructions during long-running workflows without breaking prompt cache. For agentic runs that span many steps, this can reduce cost while making it easier to steer behavior as requirements evolve.
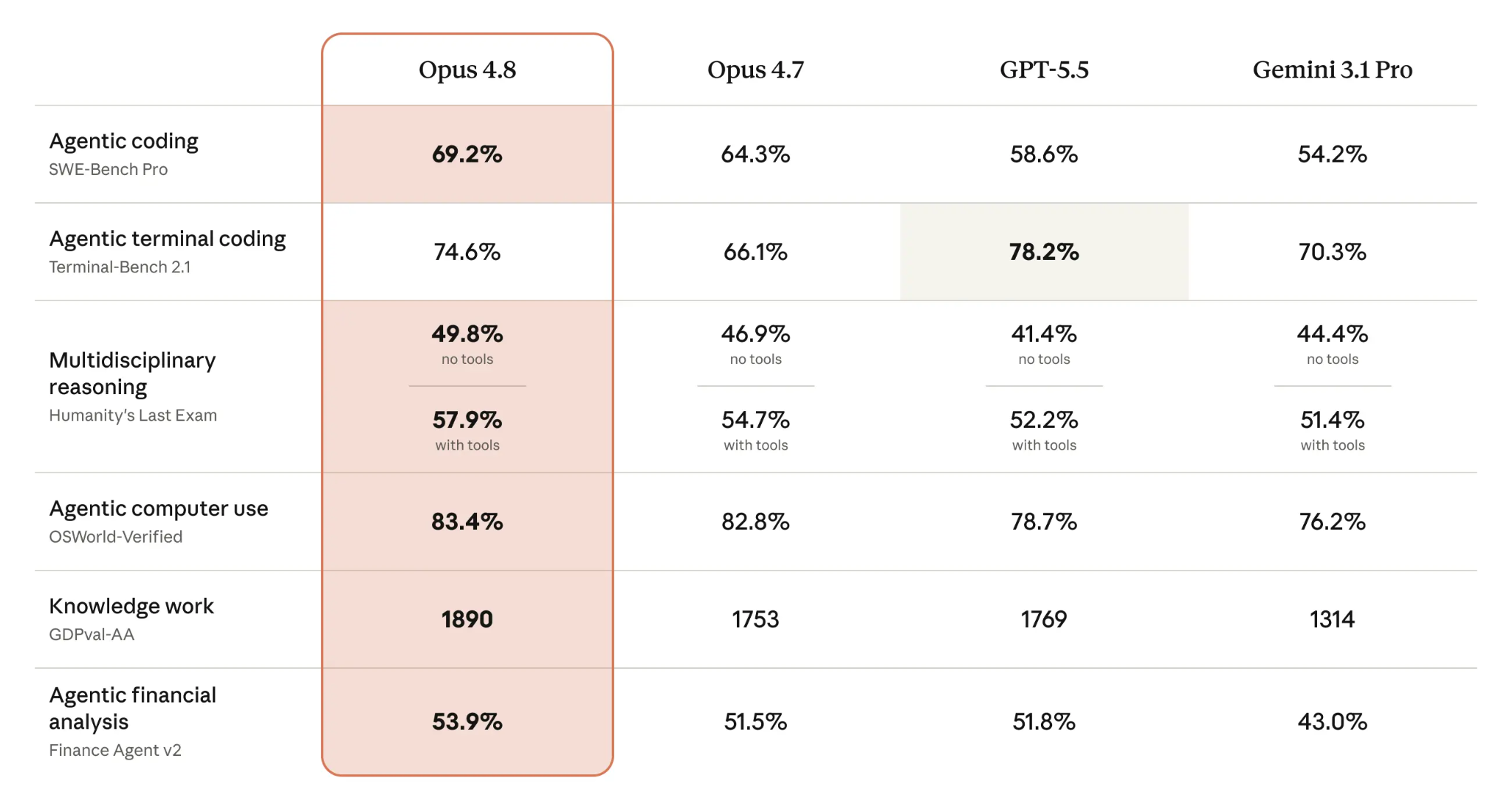
Benchmark Results: Opus 4.8 vs. Opus 4.7
Benchmarks are useful when they translate into production decisions: model reliability, completion rate, latency, and cost per successful task. For developers and AI teams, the key question is not only whether Claude Opus 4.8 scores higher than Opus 4.7, but whether it can complete more real workflows with fewer retries and less manual intervention.
The most important result is on the Super-Agent benchmark: Claude Opus 4.8 is the only model to complete every case end-to-end. It outperforms prior Opus models on full-task completion and matches GPT-5.5 on cost-adjusted performance, making it a strong option for production agent workflows where reliability and efficiency both matter.
Claude Opus 4.8 Best Use Cases
Agentic Coding & Software Engineering
Claude Opus 4.8 brings a stronger foundation for AI-assisted software engineering. It ranks #1 on the agentic coding benchmark with 69.2%, up from 64.3% for Opus 4.7, showing better performance on complex coding tasks that require planning, execution, and validation.
The improvement is especially relevant for code review. Claude Opus 4.8 is 4x less likely to miss flaws in its own generated code, which helps reduce blind spots when using AI agents for debugging, refactoring, or reviewing production code.
For B2B SaaS teams, this makes it useful for codebase migrations, multi-file refactors, dependency updates, and production debugging, where context and reliability matter.
Dynamic AI Agent Workflows
Claude Opus 4.8 is built for AI agents that need to manage complex tasks, not just answer one prompt. It can plan the work, call tools, run parallel subagents, check their outputs, and turn the final result into a structured report.
This makes it useful for workflows such as research agents, coding agents, internal copilots, and operational assistants. A typical flow could look like: plan the task, use the right tools, verify the results, then summarize what was done.
For AI builders and product teams, the key advantage is continuity. Claude Opus 4.8 can keep context and writing style across long, multi-session tasks, helping agents stay consistent over time.
Legal & Document Analysis
Claude Opus 4.8 is a strong fit for legal and compliance workflows where accuracy, traceability, and careful reasoning are essential. It achieved the highest score ever recorded on the Legal Agent Benchmark and became the first model to break 10% all-pass, showing progress on complex legal tasks that require end-to-end completion rather than isolated answers.
With a 1M token context window, teams can process entire case files, contracts, policies, or regulatory documents in a single call, reducing the need to split documents across multiple prompts. Just as importantly, Claude Opus 4.8 is designed to flag uncertainty instead of guessing, which is critical for high-stakes work where hallucinated claims can create legal, financial, or compliance risk.
Research & Knowledge Synthesis
Claude Opus 4.8 is well suited for research and knowledge synthesis workflows that require careful comparison across many sources. It can summarize papers, compare competing arguments, extract methodologies, and connect findings across documents without reducing the work to surface-level summaries.
For analysts, researchers, and strategy teams, this makes it useful for financial filings, market reports, technical papers, and internal research repositories where details matter. With a 1M token context window, teams can provide a full corpus in one call instead of splitting documents into smaller chunks, helping preserve context, structure, and source relationships across the analysis.
Enterprise Knowledge Work
Claude Opus 4.8 is designed for enterprise knowledge work where tasks often span multiple tools, files, and decision cycles. It can manage complex multi-day projects end-to-end, helping teams move from initial analysis to structured recommendations without losing context along the way.
For operations leads, AI product managers, and enterprise buyers, this is especially useful across spreadsheets, slides, and documents that require professional-grade output. Claude Opus 4.8 can analyze inputs, follow detailed instructions, and produce deliverables that match business expectations, from internal reports to executive-ready summaries.
Its improved instruction-following and style consistency also make it more reliable across long sessions, where tone, formatting, and decision criteria need to remain stable over time.
When to Use Claude Opus 4.8 vs. Lighter Models
Claude Opus 4.8 is best suited for complex, multi-step, high-stakes, or long-context tasks where reasoning quality and reliability matter more than raw speed. It is a strong choice for agentic workflows, codebase analysis, legal review, research synthesis, and enterprise knowledge work.
For simpler tasks such as classification, short summaries, routing, or basic extraction, faster and cheaper models like Haiku or Sonnet may be a better fit.
With Eden AI’s unified API, teams can switch between Opus 4.8 and lighter models with a single parameter change, without rewriting their integration.
import requests
url = "https://api.edenai.run/v2/multimodal/chat"
headers = {
"Authorization": "Bearer YOUR_EDEN_AI_API_KEY",
"Content-Type": "application/json"
}
payload = {
"providers": ["claude-opus-4-8"],
"messages": [{"role": "user", "content": "Review this code for bugs and suggest improvements."}],
"max_tokens": 1024,
"temperature": 0
}
response = requests.post(url, json=payload, headers=headers)
print(response.json())

.jpg)
.png)
%20(1).png)
