
Résumez cet article avec :
- Changer de fournisseur LLM est avant tout un problème d’intégration, pas seulement un problème de modèle. Sans passerelle, passer d’OpenAI à Anthropic, Gemini ou Mistral implique souvent de modifier les SDK, l’authentification, les endpoints, les formats de requête, le parsing des réponses et les tests.
- Une passerelle LLM compatible OpenAI permet de conserver le même SDK OpenAI et le même format de requête. Avec Eden AI, le changement principal consiste à utiliser
base_url="https://api.edenai.run/v3", à ajouter votre clé API Eden AI, puis à choisir la valeur du fournisseur et du modèle. - Le changement de fournisseur devient alors un simple changement de nom de modèle. Par exemple :
openai/gpt-4o→anthropic/claude-opus-4-8→google/gemini-2.0-flash, tandis que l’application conserve le même appelclient.chat.completions.create(). - Utiliser une passerelle devient particulièrement utile lorsque le coût des LLM, la latence, la conformité, la disponibilité ou la qualité des modèles peuvent avoir un impact en production. Pour de petits scripts internes, l’intérêt est plus limité. Mais pour les équipes produit, une passerelle LLM aide à éviter la dépendance à un seul fournisseur IA, comparer les modèles, suivre l’usage et mettre en place du fallback routing.
Une passerelle LLM compatible OpenAI permet de changer de fournisseur LLM sans modifier votre code, à part l’endpoint appelé par votre application. Vous conservez le SDK OpenAI, la même structure de requête et le même chemin d’intégration, mais vous redirigez le trafic vers une passerelle au lieu d’un fournisseur unique.
C’est important lorsque votre application a démarré avec GPT-4, puis que GPT-5 devient trop coûteux, que Claude offre de meilleurs résultats sur vos prompts, que Gemini gère mieux les longs contextes, ou que vos clients européens vous poussent à repenser le routage des données. Sans passerelle, chaque changement de fournisseur implique des différences de SDK, des modifications d’authentification, des problèmes de nommage des modèles et un travail de normalisation des réponses.
Eden AI répond à ce problème avec un simple changement de base_url : https://api.edenai.run/v3. Votre code existant compatible OpenAI peut alors accéder à 500+ modèles issus d’OpenAI, Anthropic, Gemini, Mistral et d’autres fournisseurs.
Cette approche est particulièrement utile si vous voulez éviter la dépendance à un seul fournisseur LLM ou tester le changement de fournisseur en production. Elle est moins nécessaire si un seul modèle répond déjà à vos objectifs de coût, de latence, de conformité et de qualité.
Pourquoi changer de fournisseur LLM est plus compliqué qu’il n’y paraît
Une passerelle LLM compatible OpenAI ne semble vraiment utile qu’après avoir essayé de changer de fournisseur par la méthode classique. Le problème ne vient pas uniquement de l’appel au modèle. Il vient surtout de tout ce que votre code applicatif suppose autour de cet appel.
Chaque fournisseur a son propre SDK, endpoint et format d’authentification
La plupart des équipes commencent avec un seul fournisseur parce que c’est rapide. Vous installez le SDK, ajoutez une clé API, appelez un endpoint de chat completion, puis vous mettez en production. Ensuite, vous voulez comparer un autre modèle.
OpenAI, Anthropic, Gemini, Mistral et d’autres fournisseurs exposent des SDK, endpoints, méthodes d’authentification, noms de modèles et formats de requête différents. Même lorsque deux API prennent en charge des concepts similaires, comme les messages, la température, le streaming ou les tool calls, elles les implémentent rarement exactement de la même manière.
Résultat : tester un autre modèle devient plus qu’un simple changement de configuration. Il faut souvent ajouter un second client, gérer un second chemin d’authentification et introduire une logique spécifique à chaque fournisseur dans l’application.
Le coût caché d’un changement de fournisseur
Vu de l’extérieur, changer de fournisseur LLM semble simple : remplacer le modèle A par le modèle B.
En pratique, il faut souvent réécrire le client, mettre à jour les variables d’environnement, ajuster les paramètres de requête, normaliser les schémas de réponse, gérer des objets d’erreur différents et retester les cas sensibles comme le streaming, les retries, le function calling ou les limites de tokens.
C’est pour cette raison qu’un changement qui devrait prendre une heure peut finalement prendre plusieurs jours. Le coût augmente encore lorsque les appels LLM sont intégrés à des workflows de production, des tâches en arrière-plan, des pipelines d’évaluation ou des fonctionnalités visibles par les clients.
Vous voulez peut-être changer de fournisseur LLM sans modifier votre code, mais votre intégration actuelle peut rapidement vous empêcher de le faire.
Le vrai risque : la dépendance à un fournisseur LLM
Le vendor lock-in LLM ne signifie pas seulement que vous préférez un fournisseur. Cela signifie que votre codebase rend les alternatives coûteuses à tester ou à adopter.
Cela devient un vrai problème lorsque les prix augmentent, que les limites de débit freinent votre croissance, qu’un modèle est déprécié, que la latence augmente dans une région ou qu’une panne touche un parcours critique. Vous savez qu’un autre fournisseur pourrait mieux fonctionner, mais changer implique de toucher au code de production.
Ce sujet devient important lorsque la performance, le coût ou la conformité des LLM ont un impact sur votre roadmap produit. Il est moins critique si votre usage des LLM reste faible, interne et non stratégique. Mais dès que l’IA devient une partie intégrée de votre produit, vous avez besoin d’un moyen d’éviter la dépendance à un seul fournisseur LLM avant que le coût de changement ne s’accumule.
Comment fonctionne une passerelle LLM compatible OpenAI
Une passerelle LLM ompatible OpenAI se place entre votre application et plusieurs fournisseurs de modèles. Votre application envoie une requête au format OpenAI, la passerelle la route vers le fournisseur sélectionné, puis renvoie la réponse dans le même schéma que celui déjà attendu par votre code. C’est la différence clé entre une passerelle et un simple endpoint fournisseur compatible OpenAI.
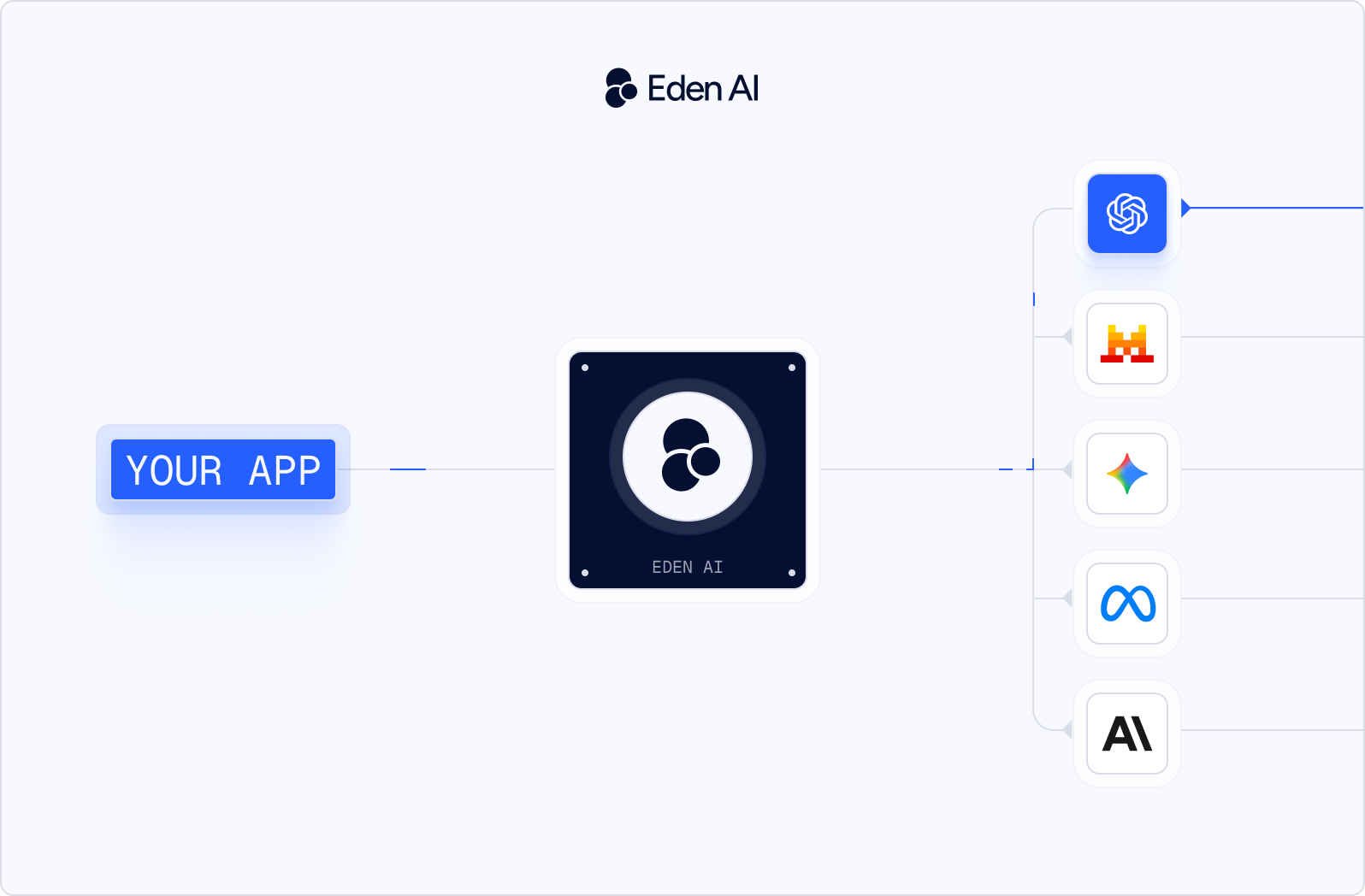
Avec une passerelle, votre application n’a pas besoin de clients spécifiques à chaque fournisseur, comme anthropic.messages.create, le SDK Gemini ou une logique d’authentification séparée pour chaque vendor. Elle conserve un seul client, une seule clé API et un seul format de requête. Le choix du fournisseur devient une décision de routage, pas une réécriture de l’application.
C’est ce qui rend le changement de fournisseur LLM réellement praticable. Vous pouvez tester GPT, Claude, Gemini, Mistral et d’autres modèles derrière la même interface, puis changer de modèle IA sans réécrire la couche d’intégration.
Une passerelle offre aussi plus de contrôle que le simple changement de fournisseur. Vous pouvez comparer plusieurs modèles sur le même prompt, suivre les coûts entre fournisseurs, définir des limites d’usage et ajouter du fallback routing lorsqu’un fournisseur renvoie des erreurs ou atteint ses limites de débit.
Cette approche est particulièrement utile lorsque les appels LLM sont intégrés à des parcours de production et que vous avez besoin de flexibilité fournisseur. Elle est moins nécessaire si vous appelez un seul modèle dans un petit script interne.
Changer de fournisseur IA en une ligne de code : avant / après
La valeur concrète d’une passerelle LLM compatible OpenAI est simple : vous pouvez conserver votre code existant avec le SDK OpenAI et modifier uniquement la destination de la requête. Au lieu de réécrire l’intégration pour chaque fournisseur, vous mettez à jour l’endpoint de la passerelle et le nom du modèle.
Avant : une intégration liée directement à OpenAI
from openai import OpenAI
client = OpenAI(api_key="sk-...")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Summarize this report."}]
)
print(response.choices[0].message.content)
Cette approche fonctionne bien tant que vous n’avez pas besoin de tester Claude, Gemini, Mistral ou un autre modèle. Mais dès que vous voulez comparer plusieurs modèles, ce qui devrait être un simple test devient un nouveau chemin d’intégration.
Après : un routage via Eden AI avec un seul changement
from openai import OpenAI
client = OpenAI(
api_key="your-edenai-api-key", # ← use your Eden AI API key
base_url="https://api.edenai.run/v3" # ← only this line changes
)
response = client.chat.completions.create(
model="anthropic/claude-opus-4-8", # ← swap this to switch providers
messages=[{"role": "user", "content": "Summarize this report."}]
)
print(response.choices[0].message.content)
C’est le principe central d’une API compatible OpenAI multi-fournisseurs. Votre application continue d’utiliser client.chat.completions.create(). Vos messages conservent la même structure role et content. Votre logique de parsing des réponses peut rester identique.
Ce qui change
Trois éléments changent : base_url, api_key et model.
Le base_url pointe désormais vers l’endpoint LLM d’Eden AI. La clé API devient votre clé Eden AI. Le modèle utilise un format provider/model-name, par exemple anthropic/claude-opus-4-8, pour indiquer à la passerelle quel fournisseur et quel modèle appeler.
Tout le reste reste stable : la structure des messages, le parsing des réponses, la plupart de la logique de streaming, les retries autour du SDK OpenAI et le code applicatif existant.
C’est ce qui permet de changer de fournisseur LLM sans modifier le code au niveau de l’intégration, et de changer de modèle IA sans réécrire le reste de votre produit.
Entre quels fournisseurs et modèles pouvez-vous basculer ?
Comme Eden AI normalise chaque fournisseur dans un même format compatible OpenAI, le changement de modèle se fait en modifiant une seule chaîne dans le champ model. Votre application conserve le même appel SDK, le même corps de requête et le même parsing de réponse, tandis que la passerelle gère les API spécifiques à chaque fournisseur en arrière-plan.
Vous obtenez ainsi une API compatible OpenAI multi-fournisseurs, sans avoir à ajouter un nouveau SDK pour chaque provider. Vous pouvez tester GPT-4o pour le raisonnement, Gemini Flash pour des workloads à faible latence, Claude pour la génération longue ou Llama pour couvrir des modèles open source, simplement en changeant la valeur du modèle.
Cette approche est particulièrement utile si vous voulez changer de modèle IA sans réécrire votre code de production ou éviter la dépendance à un seul fournisseur LLM avant que le choix du modèle ne devienne une contrainte produit.
Elle est moins nécessaire si vous avez déjà standardisé votre stack sur un seul fournisseur et que vous n’avez pas besoin de flexibilité sur le coût, la latence ou la conformité.

.jpg)


