
Summarize this article with:
- Switching providers is mainly an integration problem, not a model problem. Without a gateway, moving from OpenAI to Anthropic, Gemini, or Mistral means changing SDKs, auth, endpoints, request formats, response parsing, and tests.
- An OpenAI-compatible LLM gateway keeps the OpenAI SDK and request format unchanged. With Eden AI, the core change is
base_url="https://api.edenai.run/v3", plus the Eden AI API key and the provider/model value. - Provider switching becomes a model-name change. Example:
openai/gpt-4o→anthropic/claude-opus-4-8→google/gemini-2.0-flash, while the app keeps the sameclient.chat.completions.create()call. - Use a gateway when LLM cost, latency, compliance, uptime, or model quality can affect production. It matters less for small internal scripts, but it helps product teams avoid LLM vendor lock-in, compare models, track usage, and add fallback routing.
An OpenAI compatible LLM gateway lets you switch LLM providers without changing code beyond the endpoint your app calls. You keep the OpenAI SDK, the same request structure, and the same integration path, but point traffic to a gateway instead of a single provider.
That matters when your app started on GPT-4, then GPT-5 got expensive, Claude performed better on your prompts, Gemini gave better context handling, or EU customers pushed you to rethink data routing. Without a gateway, every provider change creates SDK differences, auth changes, model naming issues, and response normalization work.
Eden AI solves this with one base_url change: https://api.edenai.run/v3. Your existing OpenAI-compatible code can access 500+ models from OpenAI, Anthropic, Gemini, Mistral, and others.
This approach applies when you want to avoid LLM vendor lock-in or test provider switching in production. It matters less if one model already meets your cost, latency, compliance, and quality targets.
Why Switching LLM Providers Is Harder Than It Should Be
An OpenAI compatible LLM gateway only sounds useful after you try to switch providers the hard way. The problem is not the model call itself. The problem is everything your application code assumes around that call.
Every provider has its own SDK, endpoint, and auth format
Most teams start with one provider because it is fast. You install the SDK, add an API key, call a chat completion endpoint, and ship. Then you compare another model.
OpenAI, Anthropic, Gemini, Mistral, and other providers expose different SDKs, endpoints, authentication patterns, model names, and request formats. Even when two APIs support similar concepts, such as messages, temperature, streaming, or tool calls, they rarely implement them in exactly the same way.
That makes “trying another model” more than a config change. You often need a second client, a second auth path, and provider-specific logic inside your application.
The hidden cost when you need to switch
A provider switch looks simple from the outside: replace Model A with Model B.
In practice, you rewrite the client, update environment variables, adjust request parameters, normalize response schemas, handle different error objects, and retest edge cases such as streaming, retries, function calling, and token limits.
This is why a switch that should take one hour can take several days. The cost gets worse when LLM calls sit inside production workflows, background jobs, eval pipelines, or customer-facing features.
You may want to switch LLM providers without changing code, but your integration often says otherwise.
The real risk: vendor lock-in
LLM vendor lock-in does not only mean “we prefer one provider.” It means your codebase makes alternatives expensive.
That becomes a real issue when pricing changes, rate limits block growth, a model gets deprecated, latency increases in one region, or downtime hits a critical path. You know another provider might work better, but switching means touching production code.
This applies if LLM performance, cost, or compliance affects your roadmap. It matters less if your LLM usage is small, internal, and non-critical. But once AI becomes part of your product, you need a way to avoid LLM vendor lock-in before the switching cost compounds.
How an OpenAI-Compatible LLM Gateway Works
An OpenAI compatible LLM gateway sits between your application and multiple model providers. Your app sends one OpenAI-style request, the gateway routes it to the selected provider, then returns the response in the same schema your code already expects.
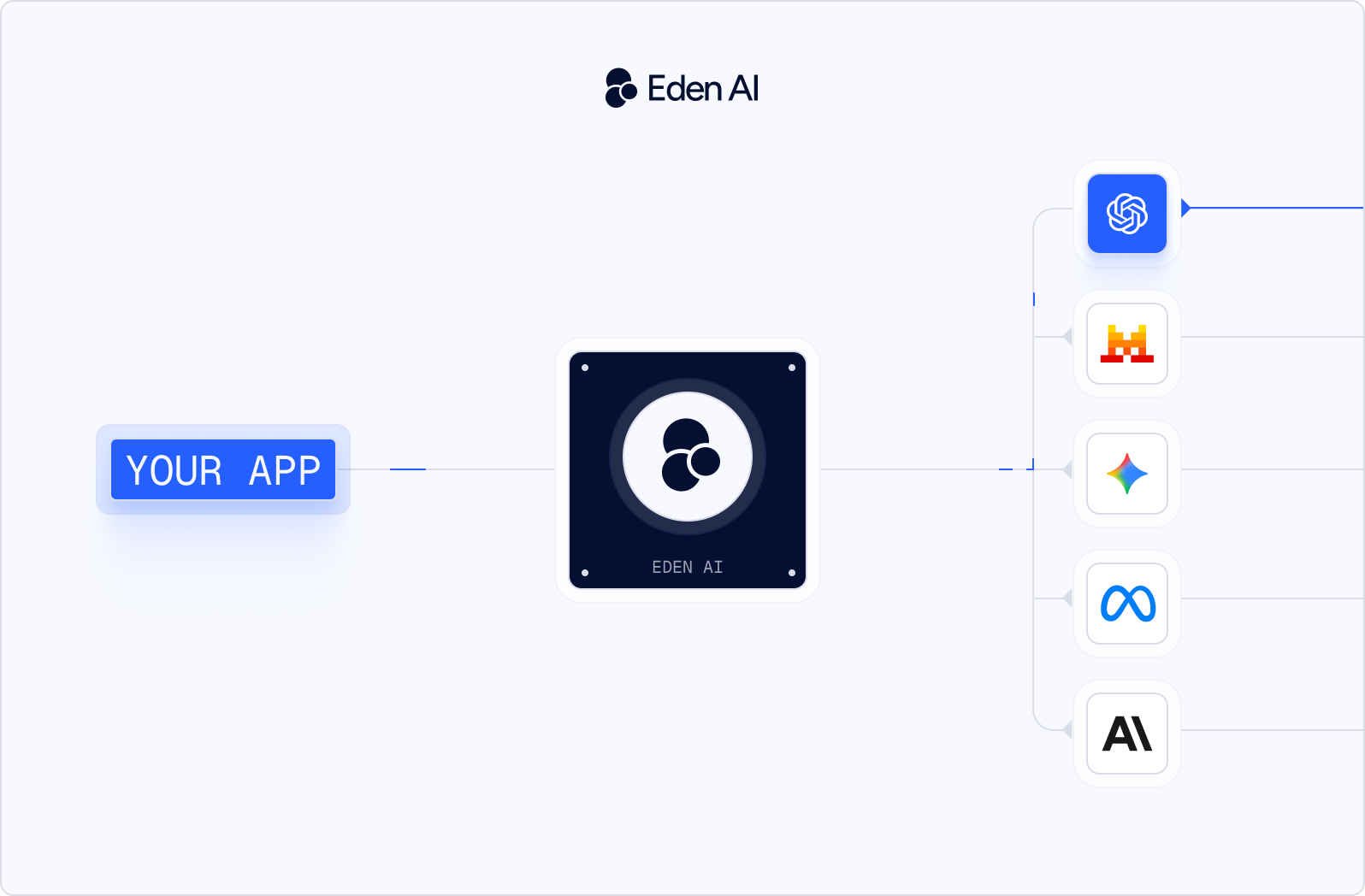
That is the key difference between a gateway and a single OpenAI-compatible provider endpoint.
With a gateway, your application does not need provider-specific clients like anthropic.messages.create, Gemini’s SDK, or separate auth logic for each vendor. It keeps one client, one API key, and one request format. The provider becomes a routing decision, not an application rewrite.
This is what makes LLM gateway provider switching practical. You can test GPT, Claude, Gemini, Mistral, and other models behind the same interface, then switch AI model without rewriting the integration layer.
A gateway also gives you control beyond switching. You can compare models on the same prompt, track cost across providers, set usage limits, and add fallback routing when one provider returns errors or hits rate limits.
This applies when LLM calls sit in production paths and you need provider flexibility. It matters less if you only call one model in a small internal script.
Switch Between AI Providers With One Line of Code: The Before and After
The practical value of an OpenAI compatible LLM gateway is simple: you can keep your existing OpenAI SDK code and change where the request goes. Instead of rewriting the integration for every provider, you update the gateway endpoint and the model name.
Before: hardcoded to OpenAI
from openai import OpenAI
client = OpenAI(api_key="sk-...")
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "Summarize this report."}]
)
print(response.choices[0].message.content)
This works well until you need to test Claude, Gemini, Mistral, or another model. At that point, a simple model comparison becomes a new integration path.
After: routed through Eden AI with one change
from openai import OpenAI
client = OpenAI(
api_key="your-edenai-api-key", # ← use your Eden AI API key
base_url="https://api.edenai.run/v3" # ← only this line changes
)
response = client.chat.completions.create(
model="anthropic/claude-opus-4-8", # ← swap this to switch providers
messages=[{"role": "user", "content": "Summarize this report."}]
)
print(response.choices[0].message.content)
This is the core pattern behind using an OpenAI compatible API multiple providers setup. Your app still uses client.chat.completions.create(). Your messages still use the same role and content structure. Your response parsing can stay the same.
What changed
Three things changed: base_url, api_key, and model.
The base_url now points to Eden AI’s LLM endpoint. The API key becomes your Eden AI key. The model uses a provider/model-name format, so anthropic/claude-opus-4-8 tells the gateway which provider and model to call.
Everything else stays stable: message structure, response parsing, most streaming logic, retries around the OpenAI SDK, and the surrounding application code. That is what lets you switch LLM providers without changing code at the integration level and switch AI model without rewriting the rest of your product.
Which Providers and Models You Can Switch Between
Because Eden AI normalizes every provider to the same OpenAI-compatible format, switching is a one-string change in the model field. Your app keeps the same SDK call, request body, and response parsing, while the gateway handles the provider-specific API behind the scenes.
This gives you an OpenAI compatible API multiple providers setup without adding a new SDK for each one. You can test GPT-4o for reasoning, Gemini Flash for lower-latency workloads, Claude for long-form generation, or Llama for open-model coverage by changing only the model value.
This matters when you want to switch AI model without rewriting production code or avoid LLM vendor lock-in before model choice becomes a roadmap constraint. It matters less if you have already standardized on one provider and do not need cost, latency, or compliance flexibility.

.jpg)


