.png)
Résumez cet article avec :
- Claude Opus 4.7 est le meilleur raisonneur lorsque les problèmes nécessitent de gérer plusieurs contraintes simultanément : analyse juridique, planification stratégique, questions de recherche complexes et multi-couches.
- Nous avons également testé GPT-5.5 et Claude Opus 4.7 directement sur la plateforme Eden AI , avec des prompts identiques dans huit catégories : raisonnement, code , écriture, résumé , gestion de longs documents et capacités multimodales, afin de vous offrir une comparaison équitable.
- Claude Opus 4.7 est le modèle le plus puissant d'Anthropic à ce jour.
- Si Claude Sonnet est le modèle polyvalent du quotidien, Opus 4.7 est celui à privilégier lorsque les enjeux sont plus élevés .
- GPT-5.5 est le dernier modèle phare d'OpenAI, conçu pour les utilisateurs qui ont besoin de plus de fiabilité , d'un meilleur suivi des instructions et d'un raisonnement plus solide que celui offert par GPT-5, sans attendre la prochaine génération complète.
Nous avons exécuté à la fois GPT-5.5 et Claude Opus 4.7 sur les mêmes tâches réelles directement sur la plateforme d’Eden AI, en utilisant des prompts identiques dans les mêmes conditions. Aucune sélection biaisée des résultats, aucun angle sponsorisé, simplement deux modèles de pointe comparés face à face sur huit catégories : raisonnement, code, rédaction, résumé, gestion de longs documents, capacités multimodales, vitesse et tarification.
Le meilleur modèle dépend presque entièrement de ce que vous cherchez réellement à faire, et l’écart entre eux varie fortement selon la tâche. Pour chaque section, vous trouverez le prompt exact utilisé, les deux sorties brutes issues d’Eden AI, ainsi qu’un verdict clair. Si vous devez choisir quel modèle utiliser, payer ou recommander à votre équipe, cette comparaison vous donnera une réponse directe.
Qu’est-ce que GPT-5.5 ?
GPT-5.5 est le dernier modèle phare d’OpenAI, conçu pour les utilisateurs qui ont besoin de plus de fiabilité, d’un meilleur suivi des instructions et d’un raisonnement plus solide que celui offert par GPT-5, sans attendre la prochaine génération complète.
Considérez-le comme GPT-5 avec les imperfections corrigées : moins d’hallucinations, une qualité de sortie plus constante, et des performances nettement améliorées sur les tâches structurées comme l’analyse et la revue de code.
Qu'est-ce que Claude Opus 4.7 ?
Claude Opus 4.7 est le modèle le plus puissant d’Anthropic à ce jour. Il est conçu pour des tâches qui nécessitent un raisonnement approfondi, une rédaction nuancée et un jugement précis -_ le type de travail où la justesse prime sur la rapidité.
Anthropic l’a entraîné avec un fort accent sur l’honnêteté et le respect strict des instructions, ce qui se reflète dans sa capacité à gérer des prompts ambigus et des documents longs et complexes. Si Claude Sonnet est le modèle polyvalent du quotidien, Opus 4.7 est celui à privilégier lorsque les enjeux sont plus élevés.
Benchmarks de performance : GPT-5.5 vs Claude Opus 4.7
Sur les benchmarks standards (MMLU, HumanEval, MATH), les deux modèles se situent dans le haut du classement, et l’écart entre eux est plus faible que ce que le marketing pourrait laisser penser. Claude Opus 4.7 a tendance à prendre l’avantage sur les tâches nécessitant un raisonnement en plusieurs étapes et une bonne rétention du contexte long.
GPT-5.5 reste très solide sur les tâches de connaissances générales et de suivi d’instructions à grande échelle. Aucun des deux modèles ne domine clairement sur tous les aspects ; le gagnant dépend presque entièrement de ce que vous leur demandez de faire.
Nous avons également testé GPT-5.5 et Claude Opus 4.7 directement sur la plateforme Eden AI, avec des prompts identiques dans huit catégories : raisonnement, code, écriture, résumé, gestion de longs documents et capacités multimodales, afin de vous offrir une comparaison équitable.
Raisonnement et résolution de problèmes complexes
Claude Opus 4.7 est le meilleur raisonneur lorsque les problèmes nécessitent de gérer plusieurs contraintes simultanément : analyse juridique, planification stratégique, questions de recherche complexes et multi-couches. Il est moins enclin à prendre des raccourcis ou à fournir une réponse incorrecte avec assurance.
GPT-5.5 est solide, mais il peut parfois échouer sur des problèmes où il devrait reconnaître “je ne suis pas sûr”, et produire à la place une réponse plausible. Si votre cas d’usage repose fortement sur la précision du raisonnement, Opus 4.7 est le choix le plus sûr.

Capacités en code
GPT-5.5 a un léger avantage sur la vitesse de génération de code et sa polyvalence : il gère avec assurance une plus grande variété de langages et de frameworks. Claude Opus 4.7 est meilleur pour déboguer et expliquer pourquoi quelque chose ne fonctionne pas, plutôt que simplement corriger.
Pour générer rapidement du boilerplate : GPT-5.5. Pour relire du code existant ou résoudre un problème d’architecture complexe : Opus 4.7. La plupart des équipes dev utilisent les deux selon le besoin.
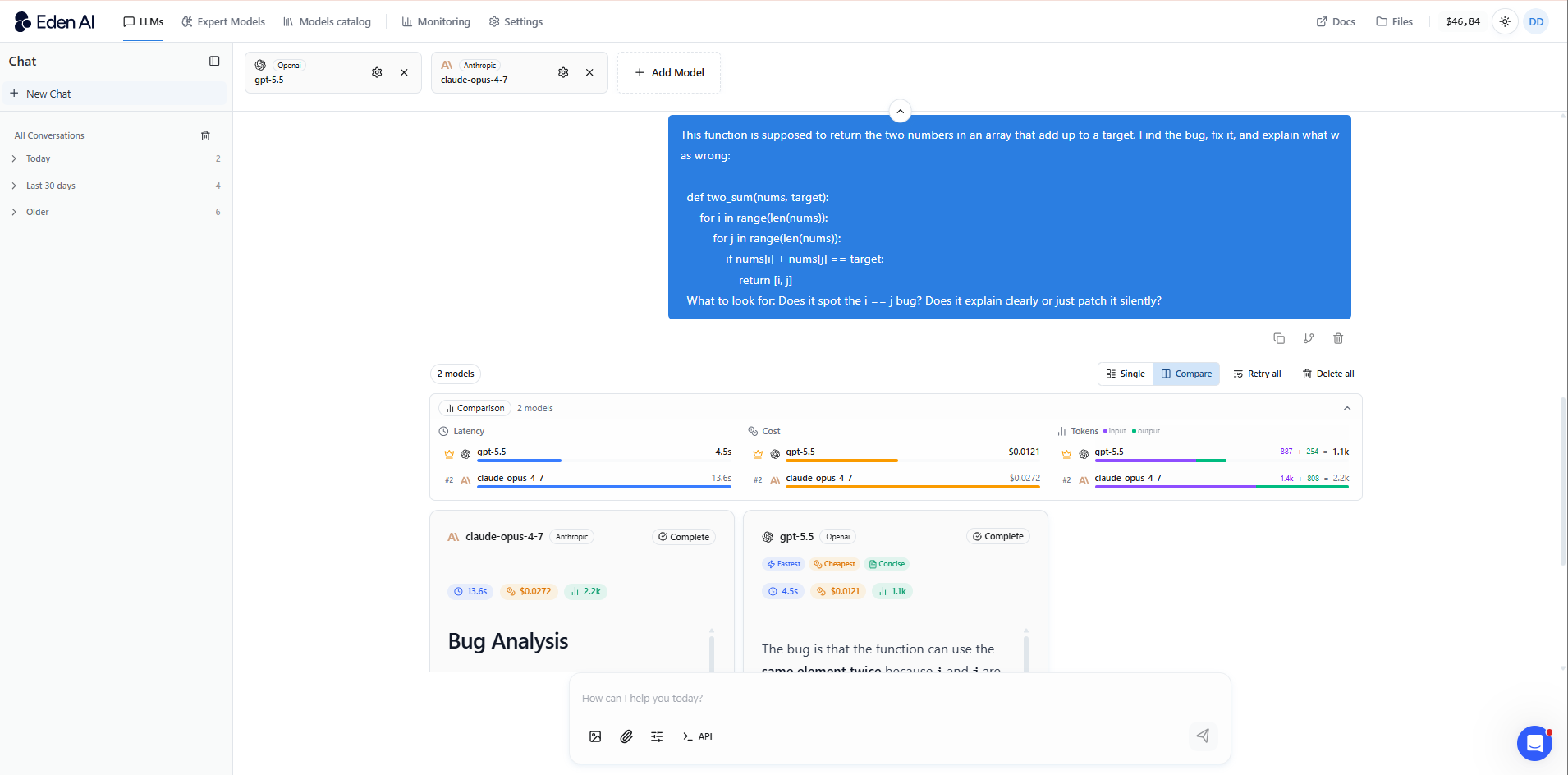
Rédaction, résumé et tâches créatives
Pour le contenu long, les résumés de recherche et tout ce qui implique une qualité de ton, Opus 4.7 est le meilleur choix. Claude Opus 4.7 produit un texte plus naturel et moins formaté, s’adapte plus précisément au brief et évite le côté parfois générique que l’on retrouve dans certaines sorties de GPT.
GPT-5.5 est plus rapide et meilleur pour suivre des templates rigides, ce qui le rend utile lorsque vous avez besoin de sorties structurées et cohérentes à grande échelle, plutôt que d’un style rédactionnel travaillé.
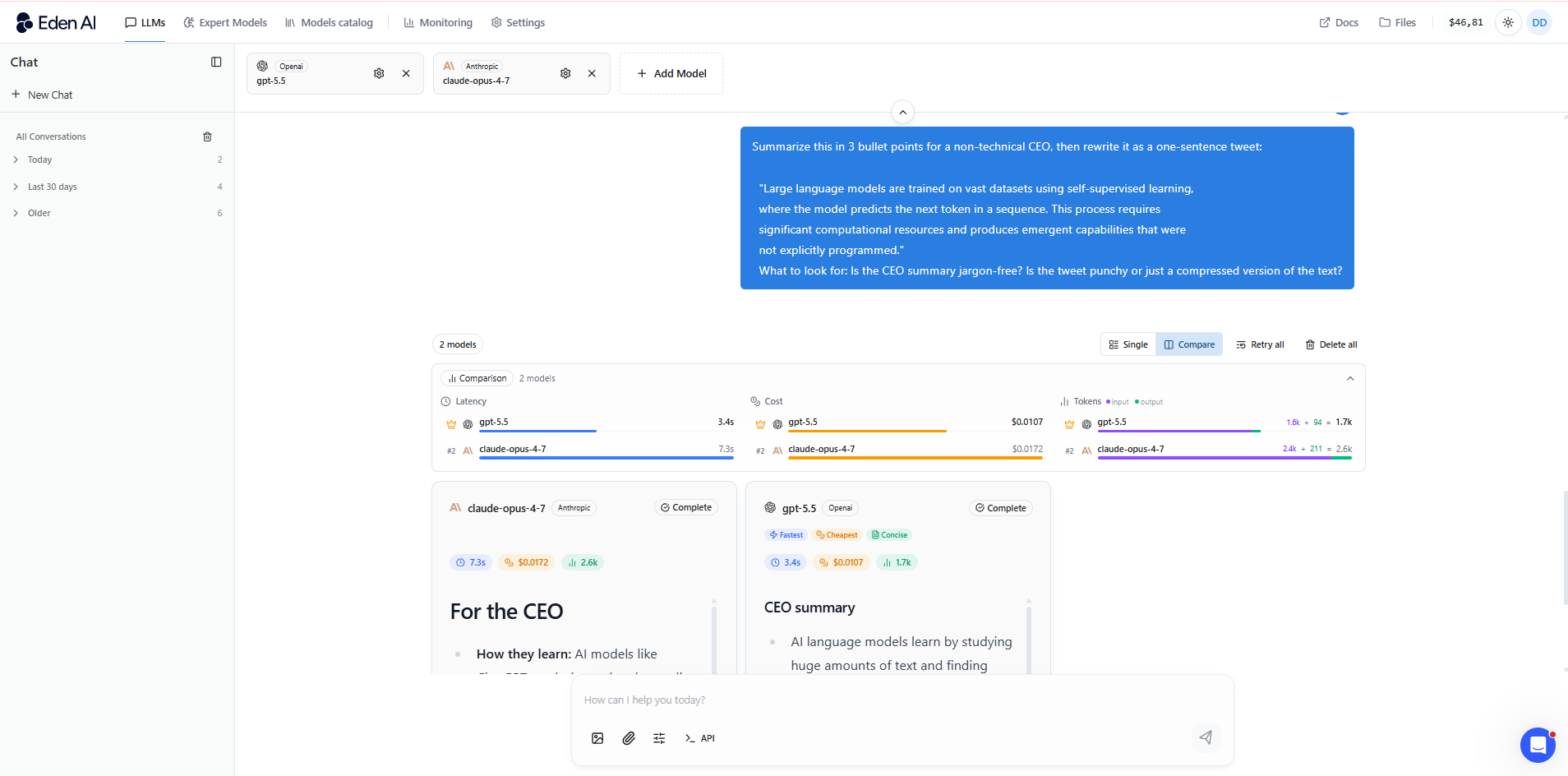
Fenêtre de contexte et gestion des longs documents
Les deux modèles supportent de larges fenêtres de contexte (200K+ tokens), mais Claude Opus 4.7 est plus fiable dans l’exploitation réelle de ce contexte. GPT-5.5 peut perdre certains détails enfouis au milieu de documents très longs - une limite connue appelée le problème du “lost in the middle”.
Si vous travaillez sur des contrats longs, des papiers de recherche ou des bases de code importantes, Opus 4.7 est l’option la plus fiable pour une compréhension de bout en bout.
Capacités multimodales : vision, audio et fichiers
GPT-5.5 dispose d’une couverture multimodale native plus large : il gère facilement images, audio et fichiers dans une seule conversation. Claude Opus 4.7 prend en charge la vision et l’analyse de documents, mais avec un périmètre multimodal plus limité.
Si votre workflow inclut des inputs multimédias ou de la voix, GPT-5.5 offre une infrastructure plus mature.
Pour des workflows principalement textuels avec un peu d’analyse d’images, Opus 4.7 répond largement aux besoins de la plupart des équipes.

Vitesse et latence : GPT-5.5 contre Claude Opus 4.7
GPT-5.5 est plus rapide pour la plupart des requêtes. Claude Opus 4.7 échange une partie de cette vitesse contre plus de profondeur : les réponses prennent légèrement plus de temps, mais nécessitent souvent moins de prompts supplémentaires pour être correctes.
En pratique :
- Si vous développez un produit en temps réel orienté utilisateur où la latence est critique, GPT-5.5 l’emporte.
- Si vous travaillez sur des workflows asynchrones ou des outils internes où quelques secondes de plus sont acceptables, le gain de qualité d’Opus 4.7 vaut le coup.
Tarification : Répartition des coûts entre GPT-5.5 et Claude Opus 4.7
Claude Opus 4.7 est généralement légèrement plus cher par token, mais la fonctionnalité de prompt caching d’Anthropic réduit fortement les coûts pour les prompts répétés ou structurés, ce qui le rend plus compétitif en production.
GPT-5.5 est plus avantageux en coût dans ⅚ des cas que nous avons testés, et propose des options tarifaires entreprise plus larges ainsi que des paliers de volume via Azure OpenAI.
Pour un usage API à grande échelle, testez les deux avec un calculateur de coût basé sur votre ratio réel prompt / output avant de faire un choix.
Utilisation de GPT-5.5 et de Claude Opus 4.7 sur une seule plateforme
Tester deux modèles phares ne devrait pas signifier gérer deux clés d’API distinctes, deux comptes de facturation et deux documentations différentes. C’est là que la plupart des équipes perdent du temps — non pas dans le travail d’IA lui-même, mais dans les contraintes autour.
Eden AI résout ce problème en vous donnant accès à GPT-5.5 et Claude Opus 4.7 via une API unique et un playground unifié. Vous pouvez exécuter le même prompt sur les deux modèles en quelques secondes, comparer les outputs côte à côte et passer de l’un à l’autre sans modifier votre intégration. Tous les tests présentés dans cet article ont été réalisés exactement de cette manière.
En pratique, c’est plus important que ça en a l’air. Les meilleures équipes ne choisissent pas un seul modèle pour toujours — elles attribuent chaque tâche au modèle le plus adapté :
- Le raisonnement complexe → Opus 4.7
- Les workflows à grande échelle → GPT-5.5
Eden AI rend ce type de bascule fluide, que vous soyez en phase d’exploration dans le playground ou en production.




