.png)
Summarize this article with:
- GPT-5.5 is OpenAI's latest flagship model, designed for users who need more reliability, better instruction-following, and stronger reasoning than GPT-5 offered, without waiting for the next full...
- Testing two flagship models shouldn't mean managing two separate API keys, two billing accounts, and two sets of documentation.
- Is GPT-5.5 better than Claude Opus 4.7?
- Eden AI's dashboard provides side-by-side benchmarks, latency metrics, and usage costs across all integrated models, enabling data-driven model selection without manual testing overhead.
- Eden AI offers a free tier with access to multiple AI providers, making it easy to compare options like GPT-5.5 and Claude Opus 4.7 Benchmarks before scaling to production volumes.
We ran both GPT-5.5 and Claude Opus 4.7 through the same real-world tasks directly on Eden AI's platform, using identical prompts under the same conditions. No cherry-picked outputs, no sponsored angles, just two flagship models going head to head across eight categories: reasoning, coding, writing, summarization, long-document handling, multimodal capabilities, speed, and pricing.
The better model depends almost entirely on what you're actually trying to do with it, and the gap between them shifts significantly depending on the task. For each section, you'll find the exact prompt we used, both raw outputs from Eden AI, and a clear verdict. If you're deciding which model to build on, pay for, or recommend to your team, this is the comparison that will give you a straight answer.
What is GPT-5.5?
GPT-5.5 is OpenAI's latest flagship model, designed for users who need more reliability, better instruction-following, and stronger reasoning than GPT-5 offered, without waiting for the next full generation.
Think of it as GPT-5 with the rough edges smoothed out: fewer hallucinations, more consistent output quality, and noticeably better performance on structured tasks like analysis and code review.
What is Claude Opus 4.7?
Claude Opus 4.7 is Anthropic's most powerful model to date. It's built for tasks that require sustained reasoning, nuanced writing, and careful judgment - the kind of work where getting it right matters more than getting it fast.
Anthropic trained it with a strong emphasis on honesty and following instructions precisely, which shows up in how it handles ambiguous prompts and long, complex documents. If Claude Sonnet is the everyday workhorse, Opus 4.7 is what you reach for when the stakes are higher.
Performance Benchmarks: GPT-5.5 vs Claude Opus 4.7
On standard benchmarks, both models score in the top tier, the gap between them is narrower than marketing would suggest. Claude Opus 4.7 tends to edge ahead on tasks requiring multi-step reasoning and long-context retention. GPT-5.5 holds its ground on general knowledge and instruction-following at scale. Neither model has a decisive lead across the board; the winner depends almost entirely on what you're asking them to do.
We also ran both GPT-5.5 and Claude Opus 4.7 directly on Eden AI's platform, using identical prompts across eight categories: reasoning, coding, writing, summarization, long-document handling, multimodal capabilities to help you have a fair comparison.
Reasoning and Complex Problem-Solving
Claude Opus 4.7 is the stronger reasoner when problems require holding multiple constraints in mind at once: legal analysis, strategic planning, layered research questions. It's less likely to take shortcuts or confidently give you a wrong answer.
GPT-5.5 is solid, but it occasionally collapses on problems that require it to say "I'm not sure" rather than produce a plausible-sounding response. If your use case lives and dies on reasoning accuracy, Opus 4.7 is the safer bet.

Coding Ability
GPT-5.5 has a slight edge on code generation speed and breadth: it handles a wider variety of languages and frameworks confidently. Claude Opus 4.7 is better at debugging and explaining why something is broken, not just patching it.
For generating boilerplate quickly: GPT-5.5. For reviewing existing code or working through a tricky architectural problem: Opus 4.7. Most dev teams end up using both depending on the task.
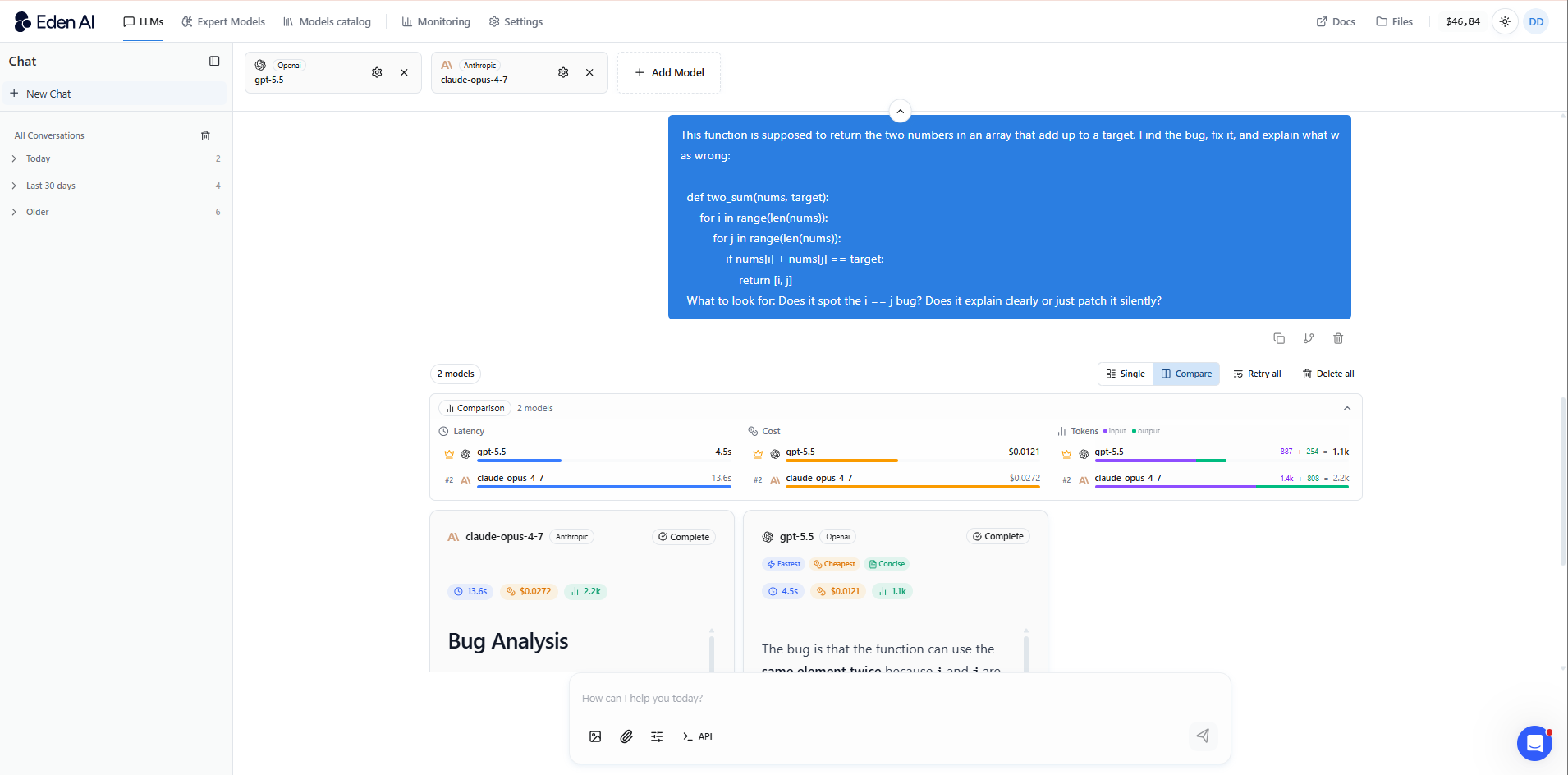
Writing, Summarization, and Creative Tasks
For long-form content, research summaries, and anything where voice matters, Opus 4.7 is the stronger choice. Claude Opus 4.7 produces more natural, less formulaic prose. It adapts tone more precisely to the brief and avoids the slightly generic quality that sometimes shows up in GPT outputs.
GPT-5.5 is faster and better at following rigid templates, useful when you need consistent structured output at volume rather than quality prose.
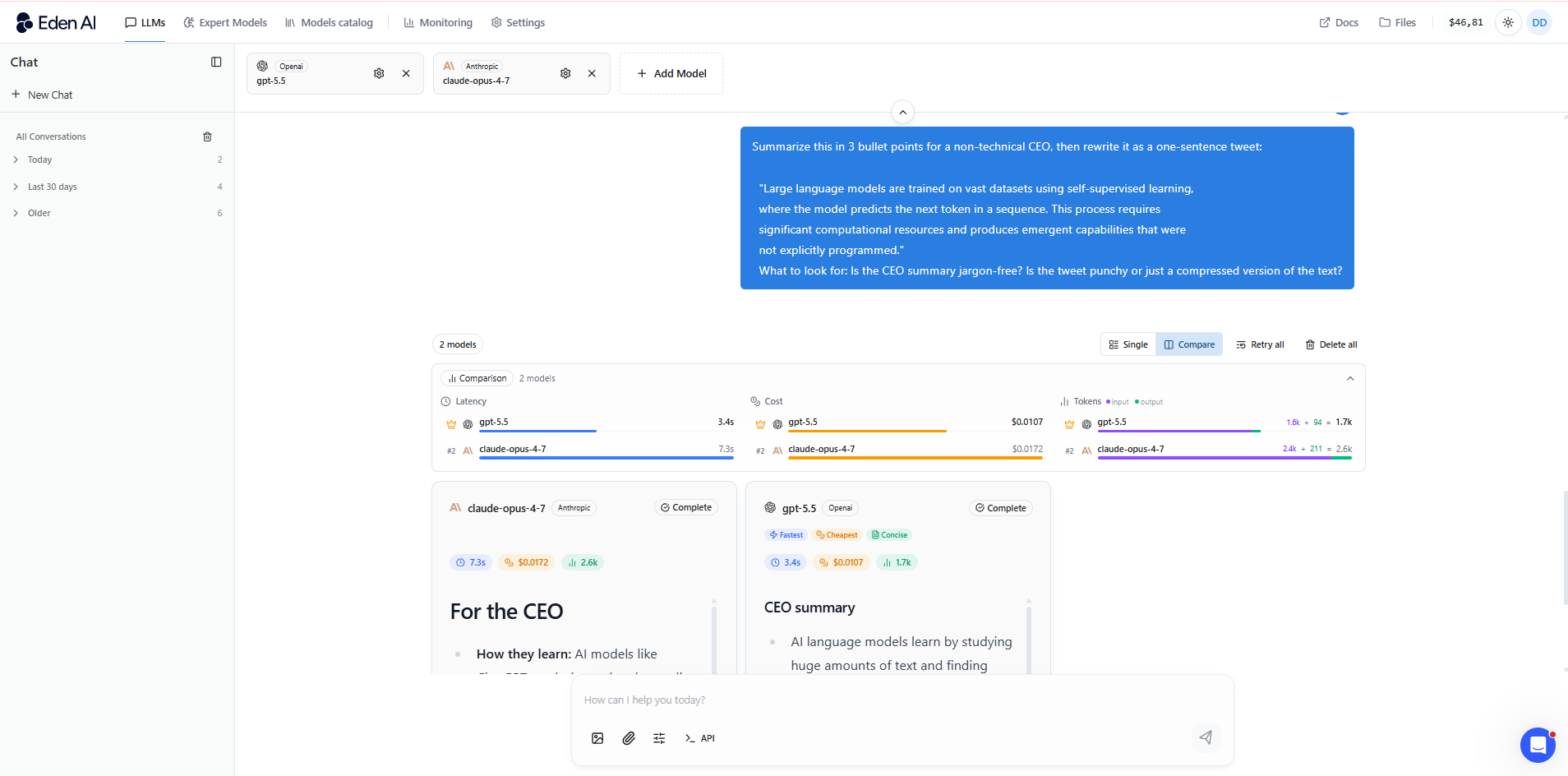
Context Window and Long-Document Handling
Both models support large context windows (200K+ tokens), but Claude Opus 4.7 is more reliable at actually using what's in the window. GPT-5.5 can lose track of details buried in the middle of very long documents, a known limitation sometimes called the "lost in the middle" problem. If you're working with lengthy contracts, research papers, or codebases, Opus 4.7 is the more trustworthy option for end-to-end comprehension.
Multimodal Capabilities: Vision, Audio, and Files
GPT-5.5 has a broader native multimodal surface: it handles images, audio, and file inputs smoothly within a single conversation. Claude Opus 4.7 supports vision and document analysis but has a narrower multimodal range compared to GPT-5.5.
If your workflow involves mixed media inputs or voice integration, GPT-5.5 has the more mature infrastructure. For text-heavy workflows with occasional image analysis, Opus 4.7 covers what most teams need.

Speed and Latency: GPT-5.5 vs Claude Opus 4.7
GPT-5.5 is faster for most requests. Claude Opus 4.7 trades some speed for depth: responses take slightly longer but tend to require fewer follow-up prompts to get right. In practice: if you're building a real-time user-facing product where latency matters, GPT-5.5 wins. If you're running async workflows or internal tools where a few extra seconds is acceptable, the Opus 4.7 quality payoff is worth it.
Pricing: GPT-5.5 vs Claude Opus 4.7 Cost Breakdown
Claude Opus 4.7 tends to cost slightly more per token, but Anthropic's prompt caching feature significantly reduces costs for repeated or structured prompts, making it more competitive for production workloads. GPT-5.5 wins for costs in ⅚ tasks we tested with two models, and has broader enterprise pricing options and volume tiers through Azure OpenAI. For high-volume API usage, run both through a cost calculator with your actual prompt/output ratio before committing.
Using GPT-5.5 and Claude Opus 4.7 in one platform
Testing two flagship models shouldn't mean managing two separate API keys, two billing accounts, and two sets of documentation. That'swhere most teams lose time: not in the AI work itself, but in the overhead around it.
Eden AI solves this by giving you access to both GPT-5.5 and Claude Opus 4.7 through a single API and a unified playground. You can run the same prompt across both models in seconds, compare outputs side by side, and switch between them without touching your integration. All the tests in this article were run exactly this way.
In practice, this matters more than it sounds. The best teams don't pick one model and commit to it forever — they route tasks to the right model depending on what's needed. Complex reasoning goes to Opus 4.7. Agentic workflows go to GPT-5.5. Eden AI makes that kind of switching frictionless, whether you're exploring in the playground or running it in production.




