
Résumez cet article avec :
- À grande échelle, la différence de coût seule peut justifier un changement de modèle , même si GPT-5.5 est légèrement plus performant sur certaines tâches .
- Sur le classement global, GPT-5.5 obtient un score de 93 contre 92 pour Gemini 3.1 Pro .
- GPT-5.5 surpasse Gemini sur l'ensemble des principaux benchmarks de code , en particulier sur les tâches complexes impliquant plusieurs fichiers , proches de situations réelles d'ingénierie plutôt que de simples exercices.
- Si vous devez traiter beaucoup de contenu, travailler avec des données visuelles ou construire un système scalable sans exploser les coûts, Gemini 3.1 Pro est aujourd'hui l'un des meilleurs choix .
- Eden AI résout ce problème en vous donnant accès à GPT-5.5 et Gemini 3.1 Pro via une API unique .
Tous les quelques mois, un nouveau modèle d’IA “meilleur que les autres” prend la tête. Aujourd’hui, deux modèles se disputent clairement cette place : GPT-5.5 et Gemini 3.1 Pro. Tous deux ont été lancés début 2026. Tous deux sont à la pointe de la technologie.
Nous avons testé ces deux modèles sur une série de cas concrets : code, raisonnement, suivi d’instructions, analyse multimodale, en utilisant Eden AI pour comparer les résultats côte à côte. ,Ce que nous avons observé : les performances ne sont pas équilibrées. Il n’y a pas un gagnant global, mais des gagnants par type de tâche. Voici ce qu’il faut retenir.
Qu'est-ce que GPT-5.5 ?
GPT-5.5 est le dernier modèle flagship de OpenAI, lancé en avril 2026. C’est le modèle à privilégier lorsque la tâche demande une réflexion approfondie en plusieurs étapes : projets de code complexes, rédaction détaillée, ou toute situation où la précision logique prime sur la rapidité.
Il est plus coûteux que ses concurrents, mais sur les bons cas d’usage, l’investissement est justifié. OpenAI a clairement optimisé cette version pour la profondeur plutôt que la polyvalence.
Idéal pour :
- Le développement et le code complexe
- Les tâches à fort raisonnement
- La rédaction longue et structurée
- Les agents IA nécessitant des instructions complexes
Qu'est-ce que Gemini 3.1 Pro ?
Gemini 3.1 Pro est le modèle haut de gamme actuel de Google. Sa principale force : sa capacité à traiter de grands volumes d’informations simultanément : documents, images, vidéos, données, tout en étant nettement plus économique à l’usage que GPT-5.5.
Si vous devez traiter beaucoup de contenu, travailler avec des données visuelles ou construire un système scalable sans exploser les coûts, Gemini 3.1 Pro est aujourd’hui l’un des meilleurs choix.
Idéal pour :
- Les tâches multimodales (texte, image, vidéo)
- L’analyse de documents volumineux
- Les workloads à grande échelle
- Les applications sensibles aux coûts
GPT-5.5 vs Gemini 3.1 Pro : benchmark face-à-face
Sur le classement global, GPT-5.5 obtient un score de 93 contre 92 pour Gemini 3.1 Pro. Autrement dit, un quasi match nul, ce qui rend l’analyse par catégorie bien plus pertinente que le score global.
Nous avons également réalisé des tests comparatifs entre GPT-5.5 et Gemini 3.1 Pro directement sur la plateforme Eden AI, en utilisant exactement les mêmes prompts sur huit catégories clés : raisonnement, code, tâches multimodales, contexte long et retrieval. Objectif : vous offrir une comparaison fiable, équitable et exploitable en conditions réelles.
Raisonnement et intelligence générale
Les deux modèles excellent, mais pas sur les mêmes types de raisonnement. Gemini est nettement plus performant lorsqu’il s’agit de résoudre des problèmes totalement nouveaux, qu’il n’a jamais rencontrés auparavant.
Sur ARC-AGI-2, un benchmark conçu pour tester la véritable capacité de résolution de nouveaux (et non la simple reconnaissance de patterns), Gemini 3.1 Pro atteint 77,1 % contre 52,9 % pour GPT-5.5. En pratique : si votre cas d’usage implique des problématiques ouvertes, ambiguës ou de type recherche, l’avantage de Gemini est réel et significatif.
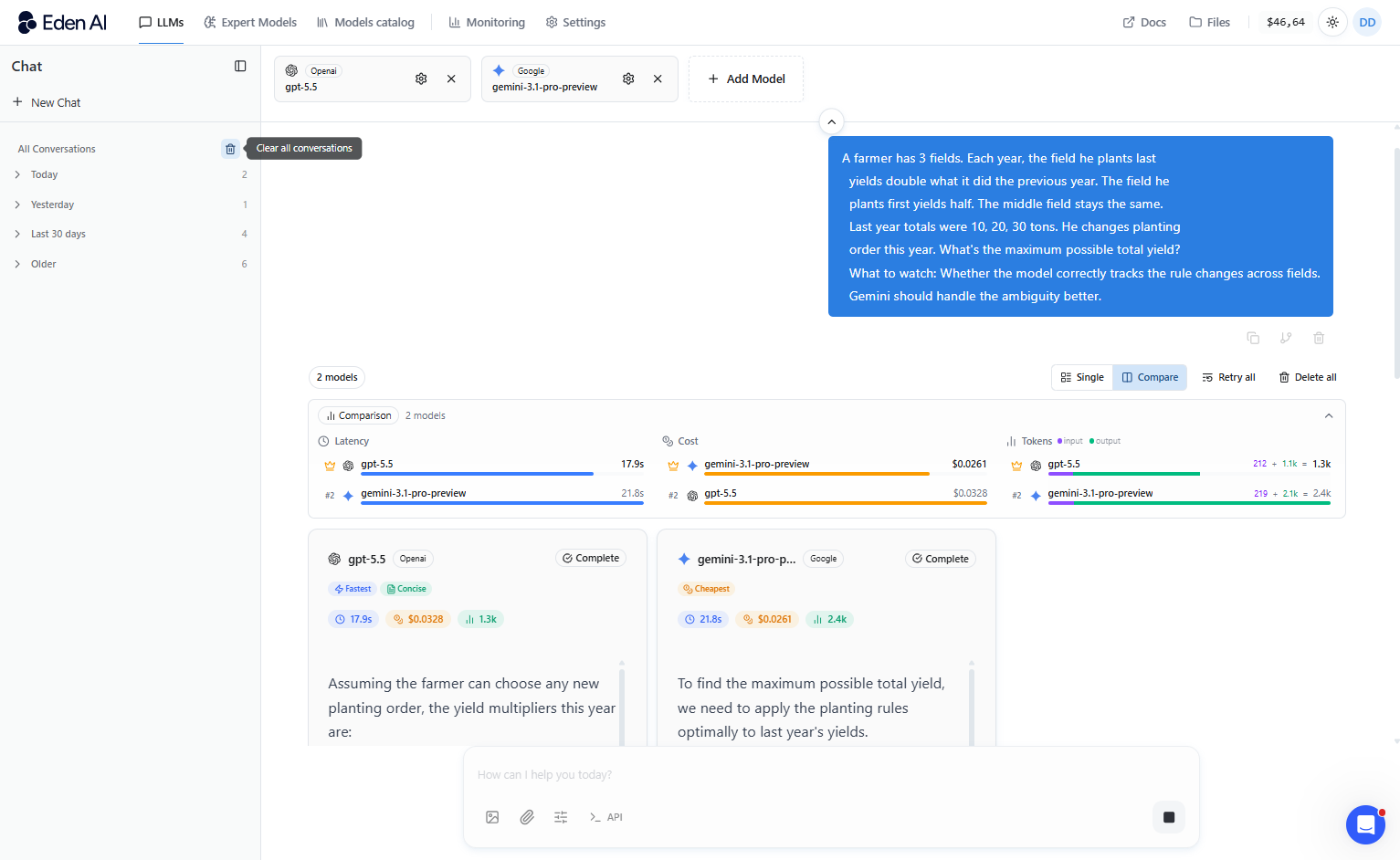
À l’inverse, GPT-5.5 est un choix plus fiable et constant pour le raisonnement structuré — mathématiques, logique en plusieurs étapes, instructions complexes - avec un score moyen de 85 contre 77 pour Gemini.
Si vous traitez des problèmes bien définis avec une structure prévisible, GPT-5.5 est l’option la plus stable.
Dans la majorité des produits, le raisonnement structuré est le cas d’usage le plus fréquent au quotidien, mais si votre travail implique des défis réellement nouveaux, il ne faut pas sous-estimer l’avantage de Gemini sur ce point.
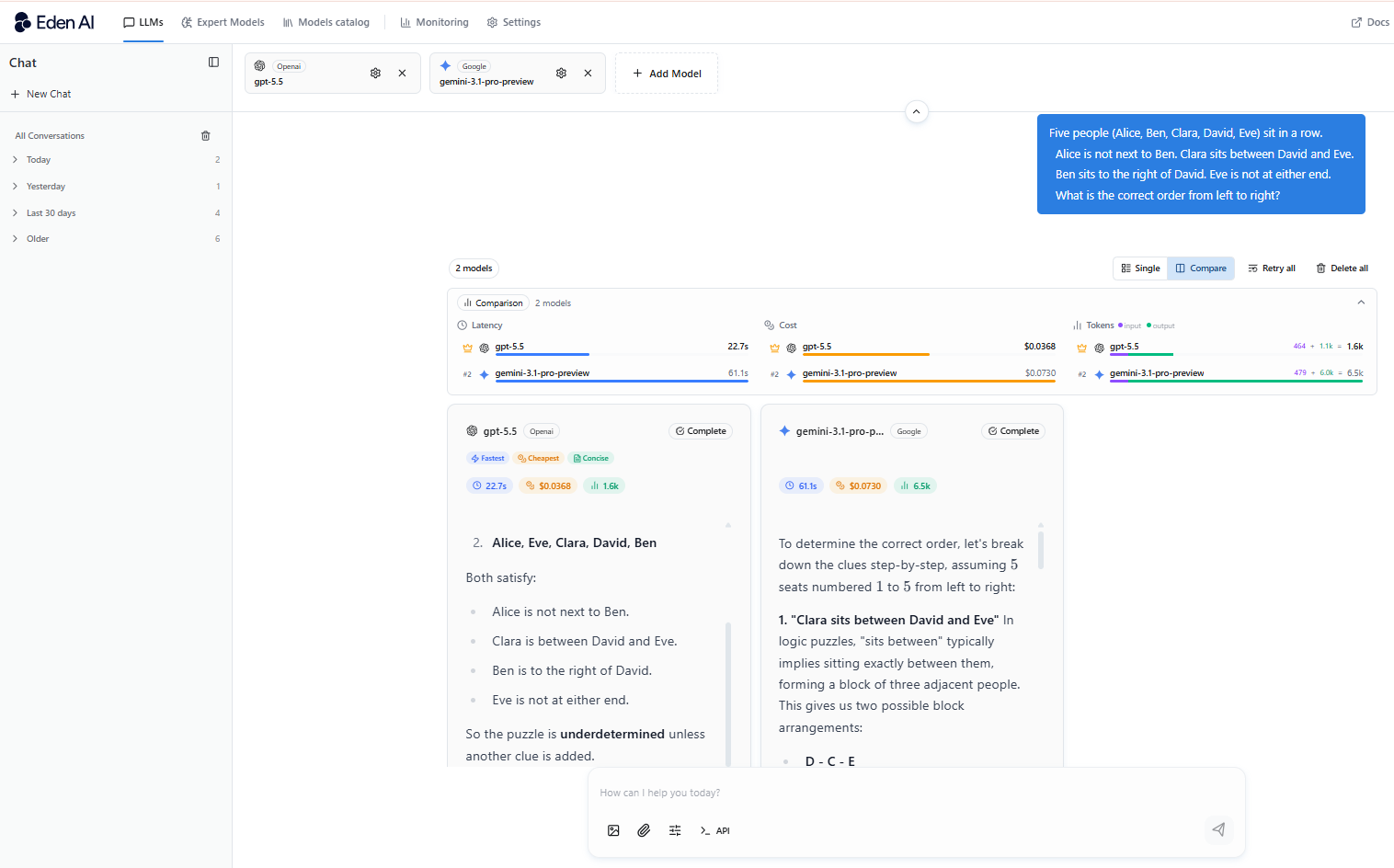
Performance de code
GPT-5.5 surpasse Gemini sur l’ensemble des principaux benchmarks de code, en particulier sur les tâches complexes impliquant plusieurs fichiers, proches de situations réelles d’ingénierie plutôt que de simples exercices.
Les développeurs constatent de manière récurrente que GPT-5.5 produit un code plus propre, détecte davantage de bugs et suit des instructions complexes avec plus de fiabilité.
Si vous développez un assistant de code, un outil de code review, ou toute application où le code doit réellement fonctionner, GPT-5.5 est le choix le plus sûr.
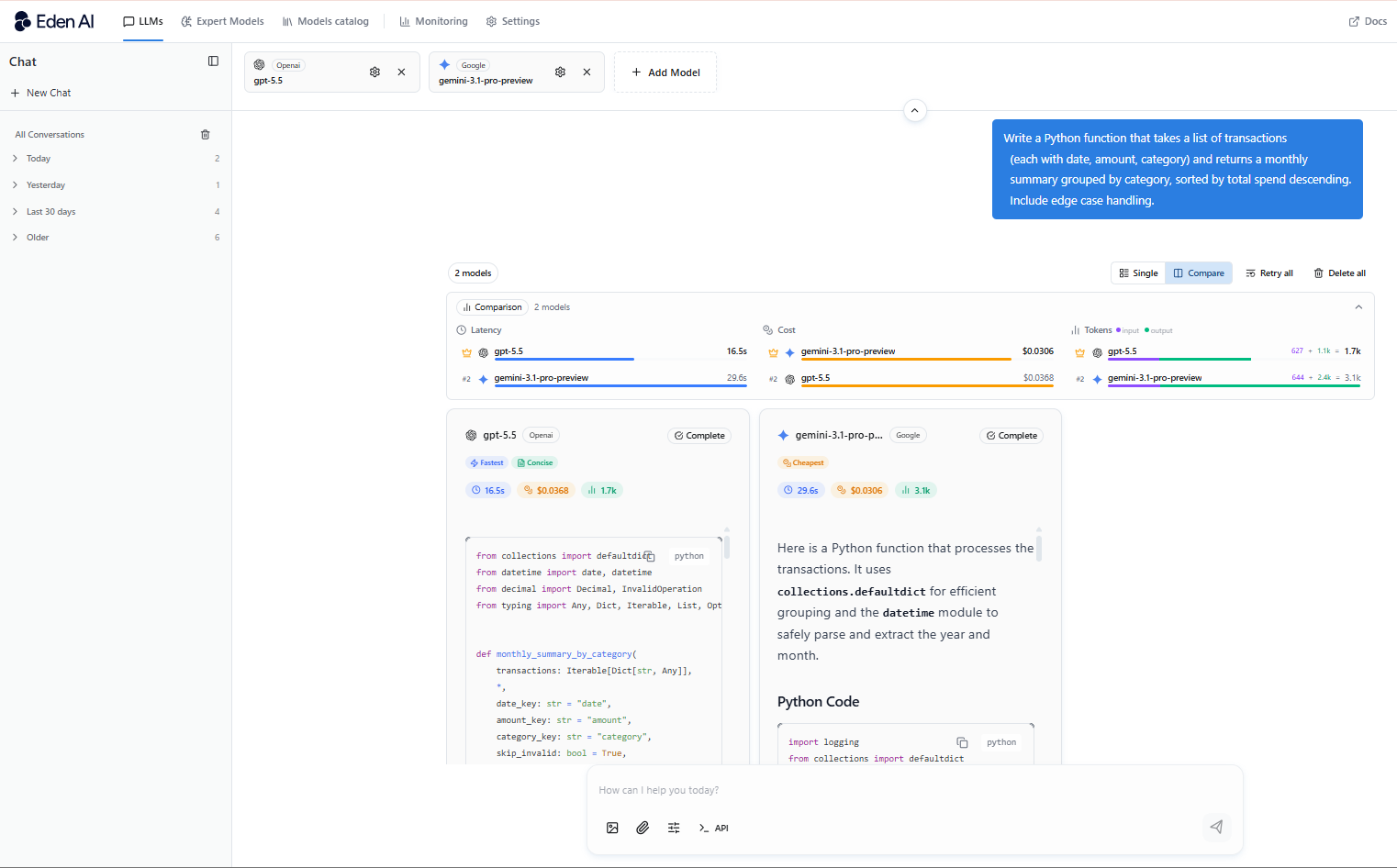
Tâches multimodales
Gemini obtient un score de 82,8 contre 70,4 pour GPT-5.5 sur les tâches multimodales: soit un écart de 17 % qui se ressent concrètement en pratique.
Si vous travaillez avec des images, des PDF, des tableurs, des présentations ou tout mélange de formats, Gemini les traite avec plus de précision et moins de friction. Cela fait de Gemini le choix le plus pertinent pour :
- Les outils de traitement de documents
- Les assistants de recherche
- Les pipelines d’extraction de données
- Tout produit où les utilisateurs uploadent des fichiers
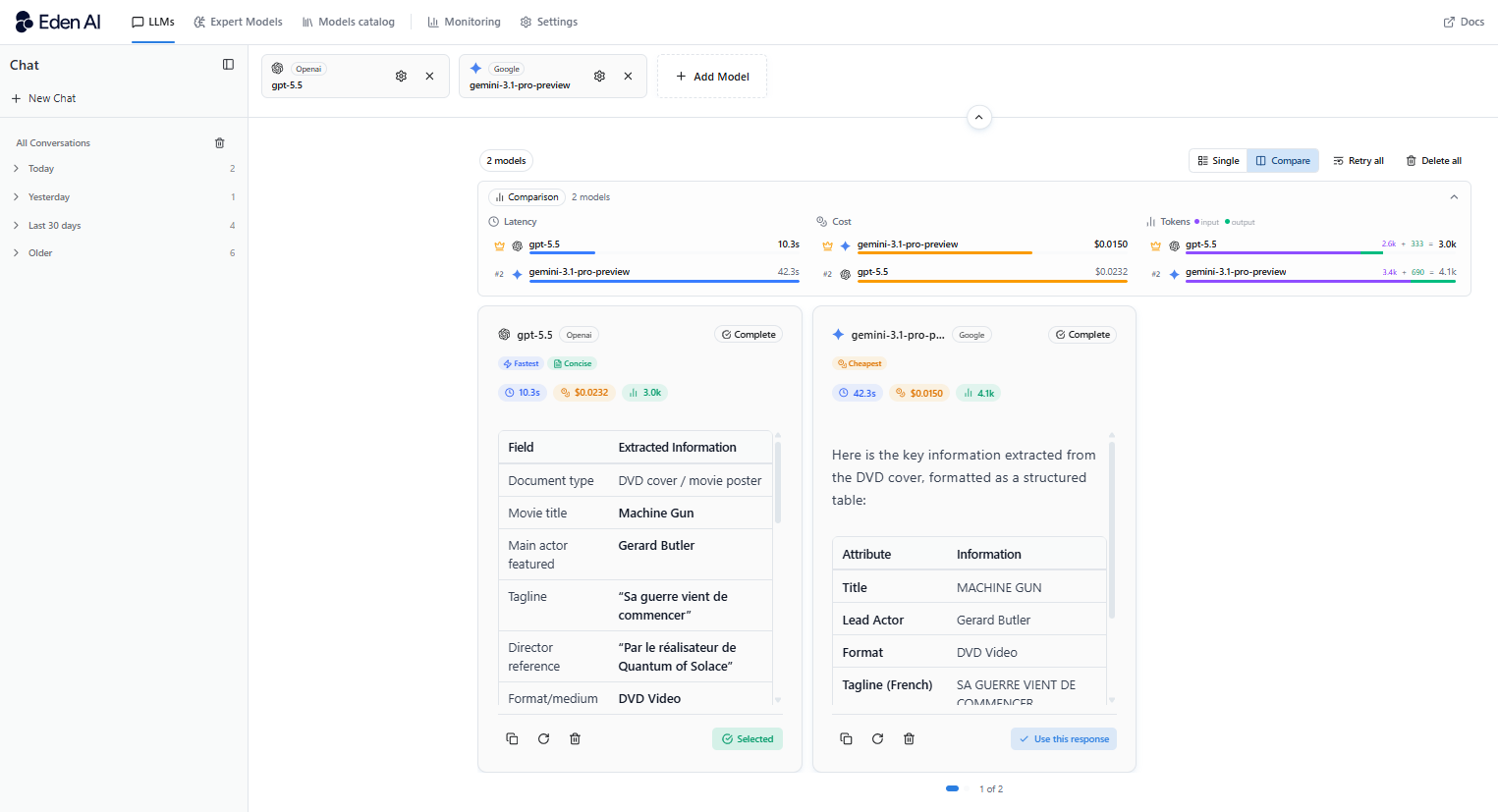
Contexte long et retrieval
Les deux modèles peuvent techniquement gérer jusqu’à un million de tokens en contexte, mais Gemini a été conçu spécifiquement pour le retrieval sur de longs contextes. Il gère les documents volumineux de manière plus constante, sans perdre des informations importantes enfouies dans le contenu.
Pour RAG (retrieval-augmented generation) systèmes, les bases de connaissances ou les applications qui doivent raisonner sur plusieurs documents simultanément, Gemini est la base la plus fiable.
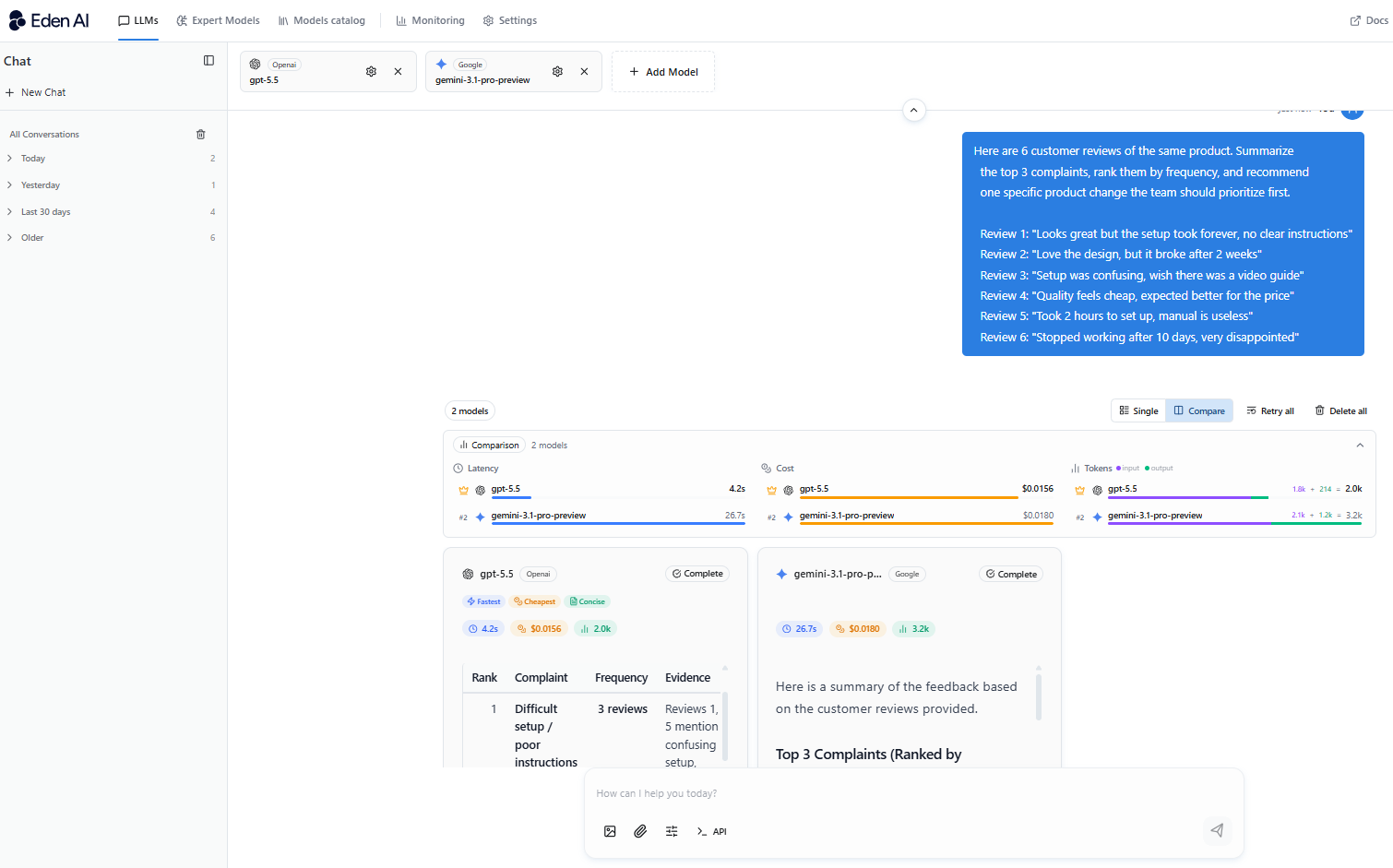
Comparaison des coûts et de la latence : GPT-5.5 contre Gemini 3.1 Pro
Gemini est environ 2 à 2,5 fois moins cher sur les tokens de sortie. Or, ce sont ces tokens qui représentent la majorité des coûts API, ce qui amplifie rapidement l’écart.
En pratique, la différence est encore plus marquée : avec 30 $ vs 12–15 $, Gemini est 2 à 2,5 fois moins cher là où cela compte le plus.
Exemple concret :
Si votre application génère 5 millions de tokens de sortie par jour — un volume réaliste pour un produit de résumé ou de chat en production :
- GPT-5.5 : ~4 500 $ / mois
- Gemini 3.1 Pro : ~1 800 à 2 250 $ / mois
Cela représente 2 000 à 2 700 $ d’économies chaque mois.
À grande échelle, la différence de coût seule peut justifier un changement de modèle, même si GPT-5.5 est légèrement plus performant sur certaines tâches.
Pour la latence, lors de nos tests directs sur Eden AI, GPT-5.5 s’est montré plus rapide dans tous les cas, y compris sur des prompts complexes en plusieurs étapes, où l’on pourrait s’attendre à des temps de traitement plus longs.
C’est un point important, car cela va à l’encontre de l’idée reçue selon laquelle un modèle moins cher est forcément plus rapide. La latence de Gemini 3.1 Pro est notamment en retrait sur les tâches de raisonnement structuré et de suivi d’instructions.
Pour les applications orientées utilisateur, où la rapidité de réponse impacte directement l’expérience, GPT-5.5 combine avantage de qualité et de vitesse. Les économies offertes par Gemini sont réelles, mais si la latence est un critère clé en plus de la qualité, le choix de GPT-5.5 devient plus évident : vous ne payez pas seulement pour de meilleurs résultats, mais aussi pour des réponses plus rapides.
Utiliser GPT-5.5 et Gemini 3.1 Pro sur une seule plateforme
Tester deux modèles flagship ne devrait pas signifier gérer deux clés API distinctes, deux comptes de facturation et deux documentations différentes. C’est précisément là que la plupart des équipes perdent du temps : non pas sur l’IA elle-même, mais sur toute la complexité autour.
Eden AI résout ce problème en vous donnant accès à GPT-5.5 et Gemini 3.1 Pro via une API unique. Vous pouvez exécuter le même prompt sur les deux modèles en quelques secondes, comparer les résultats côte à côte et passer de l’un à l’autre sans modifier votre intégration. Tous les tests présentés dans cet article ont été réalisés de cette manière.
Dans la pratique, cela est plus important qu'il n'y paraît. Les meilleures équipes ne choisissent pas un modèle et ne s'y engagent pas pour toujours. Elles confient les tâches au bon modèle en fonction des besoins. Eden AI facilite ce type de commutation, que vous exploriez sur le terrain de jeu ou que vous l'utilisiez en production.




