
Summarize this article with:
- Gemini 3.1 Pro is Google's current top-tier model.
- That's $2,000 - $2,700 saved every month.
- The right choice depends on your latency requirements, budget, and task type.
- Eden AI's dashboard provides side-by-side benchmarks, latency metrics, and usage costs across all integrated models, enabling data-driven model selection without manual testing overhead.
- Eden AI offers a free tier with access to multiple AI providers, making it easy to compare options like GPT-5.5 and Gemini 3.1 Pro Benchmarks before scaling to production volumes.
Every few months a new "best AI model" takes the crown. Right now, two models are fighting for it: GPT-5.5 and Gemini 3.1 Pro. Both were released in early 2026. Both sit at the frontier.
We ran both models through a series of real tasks: coding, reasoning, instruction following, multimodal analysis using Eden AI to compare outputs side by side. What we found is that the models don't split evenly. The result: clear winners by task, not by model. Here's what we found.
What is GPT-5.5?
GPT-5.5 is OpenAI's latest flagship model, released in April 2026. It's the model you reach for when the task requires careful, multi-step thinking - complex coding projects, detailed writing, or anything where getting the logic right matters more than getting the answer fast.
It's more expensive than its competitors, but for the right workloads, it earns it. OpenAI has clearly optimized this version for depth over breadth.
Best for: Coding, reasoning-heavy tasks, long-form writing, AI agents that need to follow complex instructions.
What Is Gemini 3.1 Pro?
Gemini 3.1 Pro is Google's current top-tier model. Its standout feature is how well it handles large amounts of information at once - documents, images, video, and data - while being significantly cheaper to run than GPT-5.5.
If you're processing a lot of content, working with visual data, or building something that needs to run at scale without breaking the budget, Gemini 3.1 Pro is hard to beat right now.
Best for: Multimodal tasks, large document analysis, high-volume production workloads, cost-sensitive applications.
GPT-5.5 vs Gemini 3.1 Pro: Head-to-Head Benchmarks
On the overall leaderboard, GPT-5.5 scores 93 versus Gemini 3.1 Pro's 92. Essentially a tie - which is why looking at the category breakdowns matters far more than the headline number.
We also run tests comparing GPT-5.5 and Gemini 3.1 Pro directly on Eden AI's platform, using identical prompts across eight categories: reasoning, coding, multimodal task, long-context and retrieval tasks to help you have a fair comparison.
Reasoning and General Intelligence
The two models perform well on different kinds of reasoning. Gemini is meaningfully better at working through problems it hasn't seen before.
On ARC-AGI-2, the benchmark that tests genuine novel problem-solving, not pattern recall - Gemini 3.1 Pro scored 77.1% against GPT-5.5's 52.9%. In practice: if your use case involves open-ended, ambiguous, or research-style thinking, Gemini's edge is real.
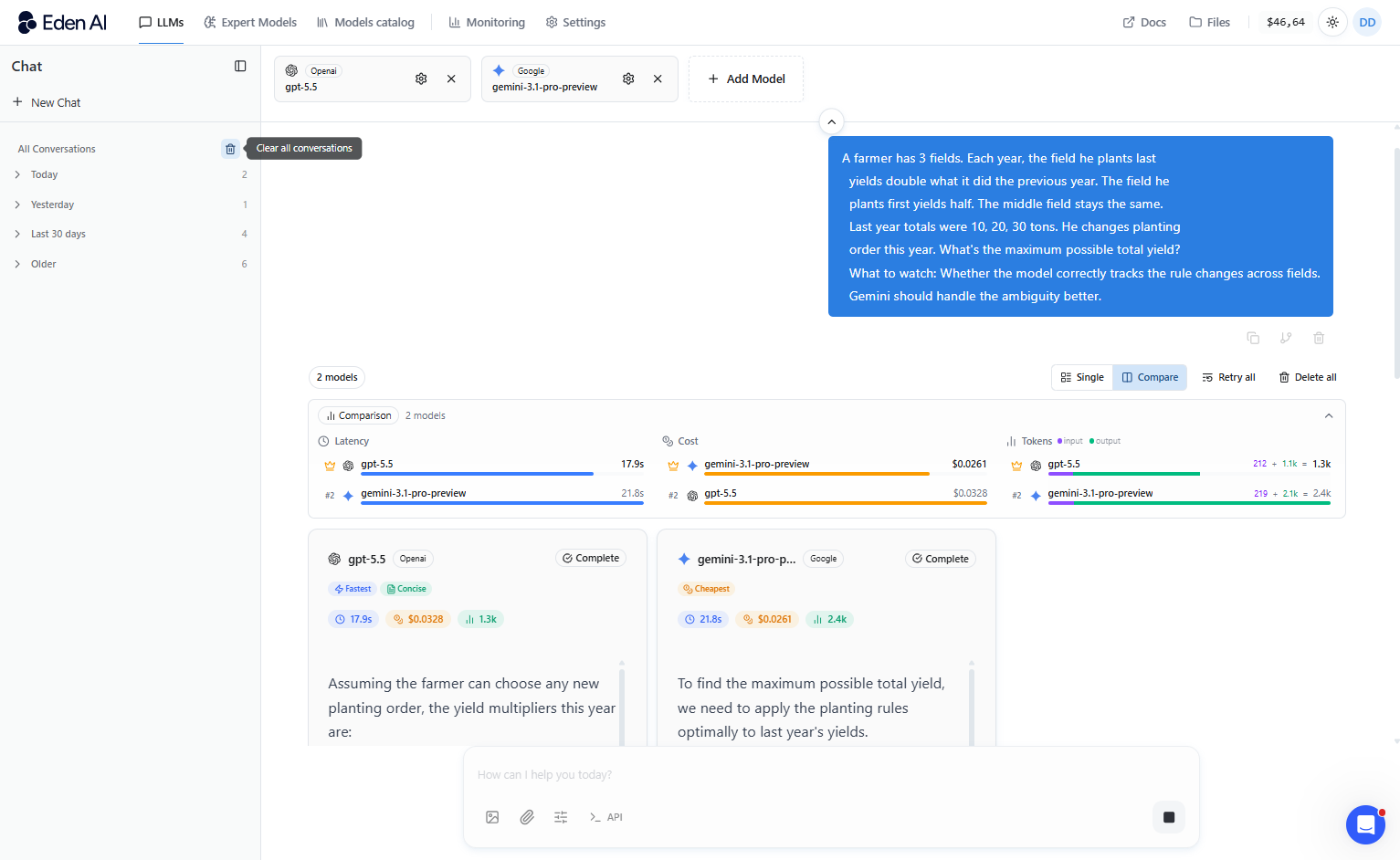
Otherwise, GPT-5.5 is a more consistent choice for structured reasoning - math, multi-step logic, layered instructions, with its score averages 85 versus Gemini's 77. If you're solving well-defined problems with predictable structure, GPT-5.5 is the steadier option. For most products, structured reasoning is what you'll hit daily - but if your work involves genuinely novel challenges, don't dismiss Gemini's lead here.
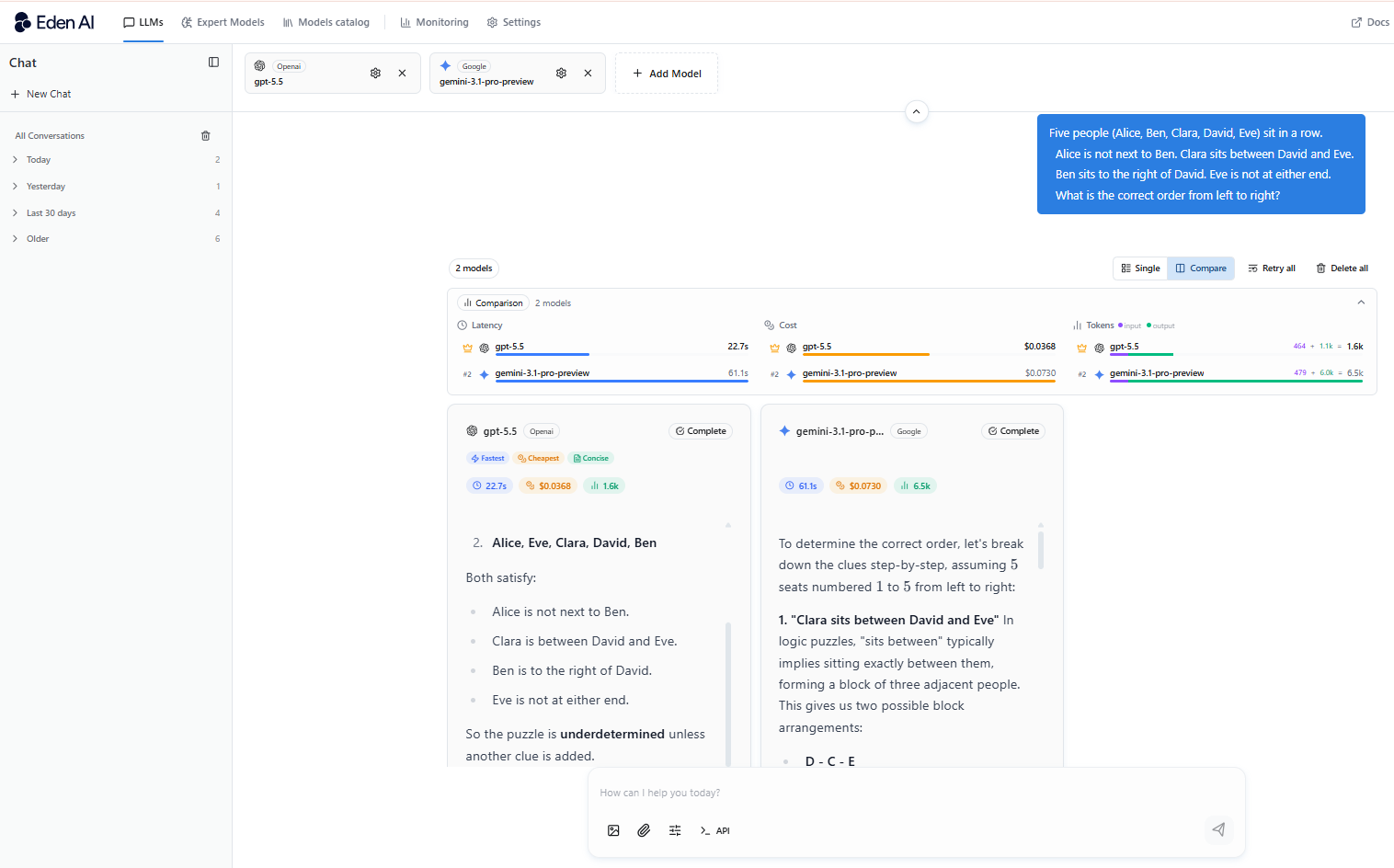
Coding Performance
GPT-5.5 outperforms Gemini on every major coding benchmark - particularly on complex, multi-file tasks that resemble real engineering work rather than toy problems. Developers consistently report that GPT-5.5 writes cleaner code, catches more bugs, and follows intricate instructions more reliably.
If you're building a coding assistant, a code review tool, or anything where the output is code that actually needs to run, GPT-5.5 is the safer bet.
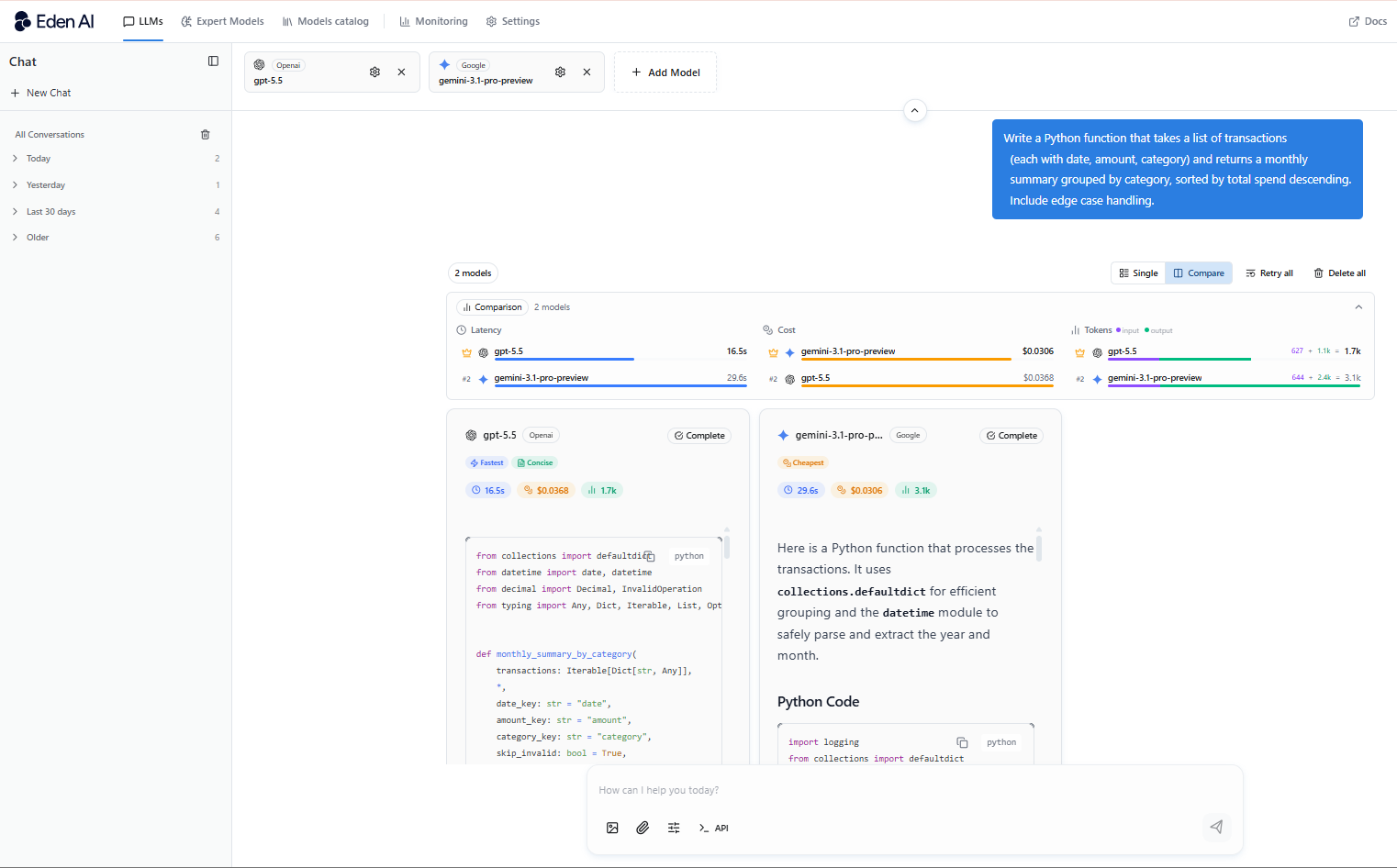
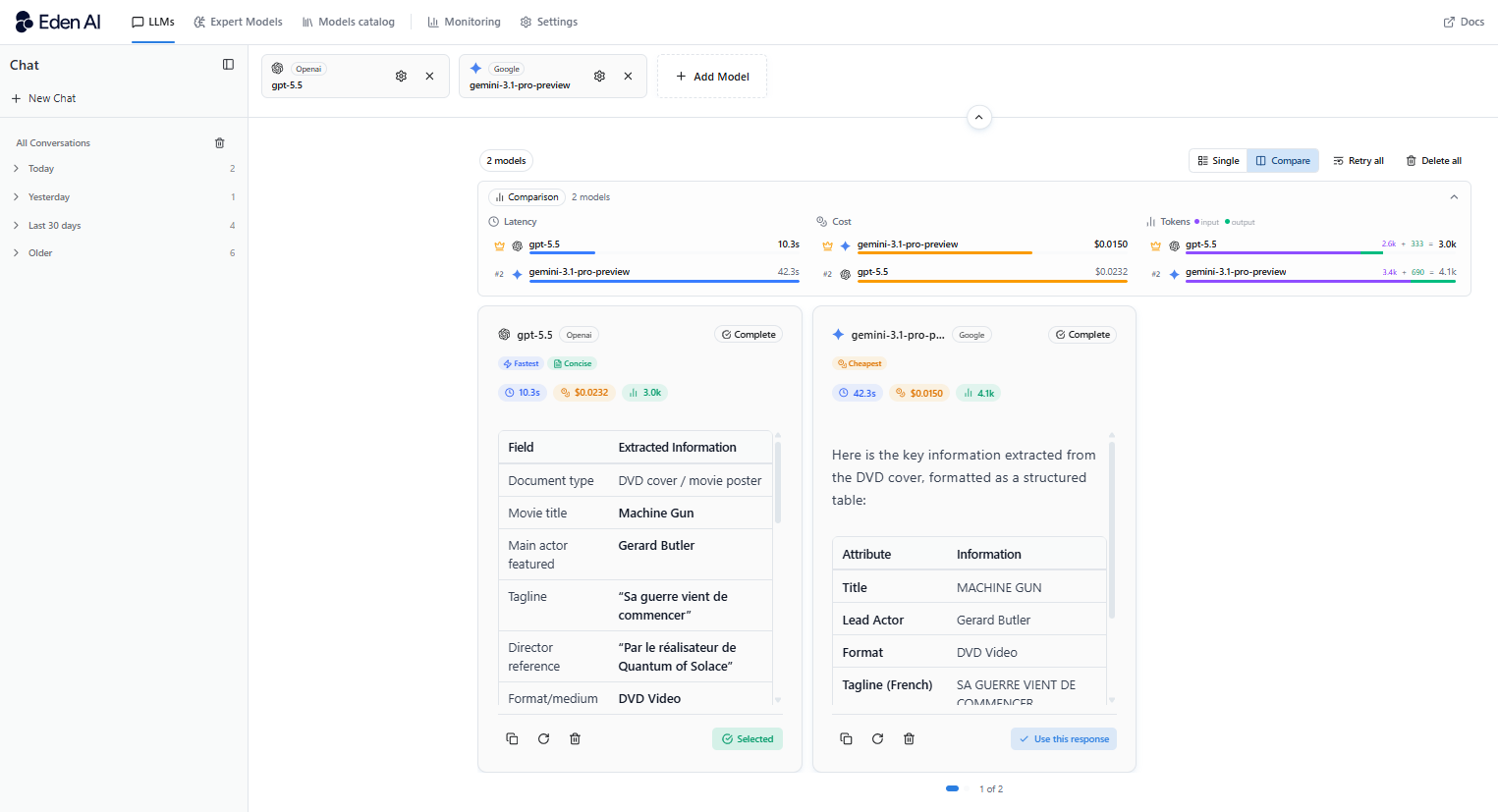
Multimodal Tasks
Gemini scores 82.8 versus GPT-5.5's 70.4 on multimodal tasks - a 17% gap that shows up in practice. If you're working with images, PDFs, spreadsheets, slides, or any mix of content types, Gemini handles them more accurately and with less friction.
This makes Gemini the stronger choice for document processing tools, research assistants, data extraction pipelines, or any product where users upload files.
Long-Context and Retrieval
Both models can technically fit a million tokens in context, but Gemini was designed with large-context retrieval in mind. It handles long documents more consistently without losing track of details buried deep in the context.
For RAG (retrieval-augmented generation) systems, knowledge bases, or applications that need to reason across many documents at once, Gemini is the more reliable foundation.
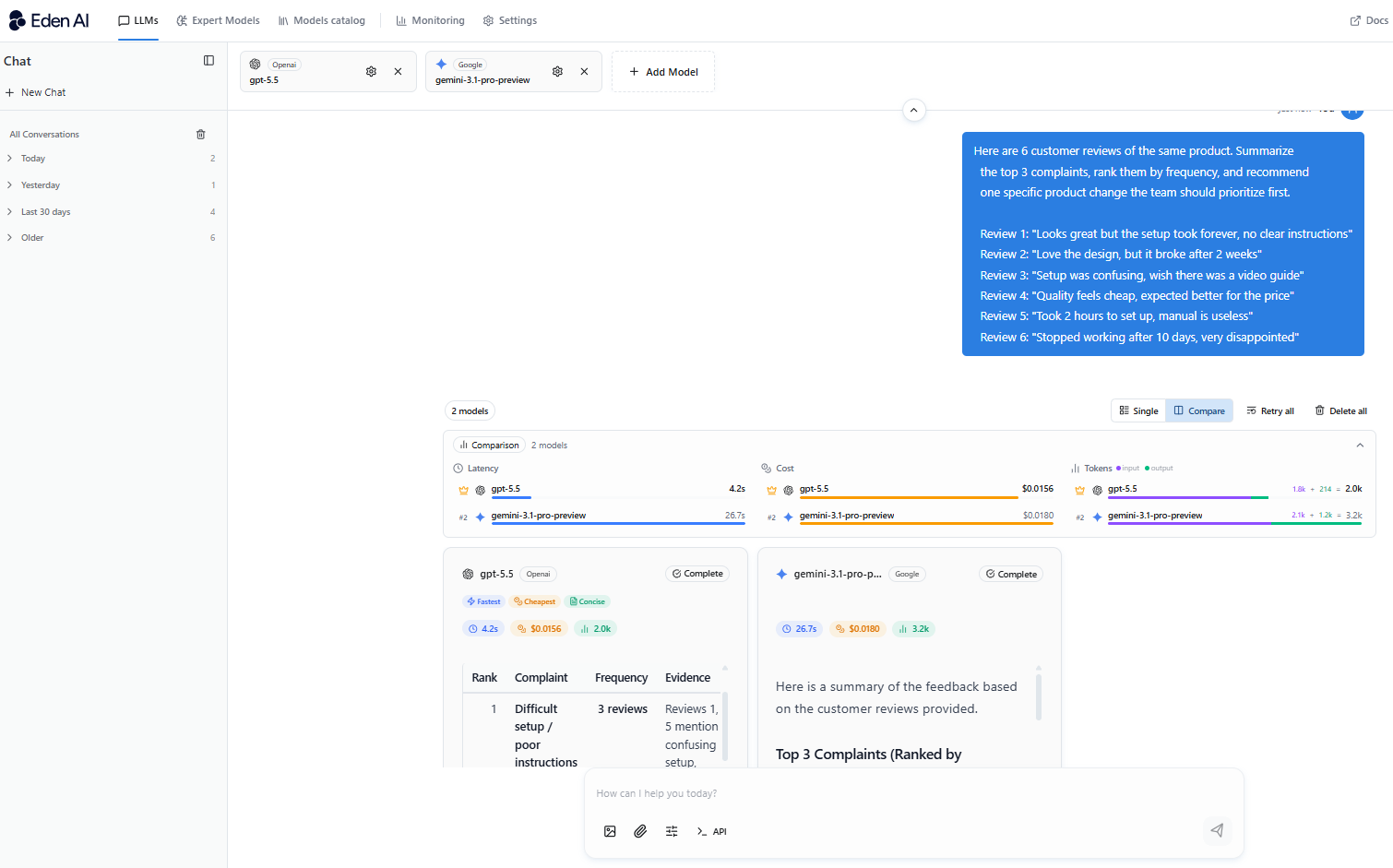
Cost & Latency Comparison: GPT-5.5 vs Gemini 3.1 Pro
Gemini is roughly 2-2.5x cheaper on output tokens. Since output is where most API costs accumulate, this gap compounds fast. In practice, it's larger - because most API costs come from output tokens, and at $30 vs $12–15, Gemini is 2 to 2.5x cheaper where it counts most.
A real-world example: if your application generates 5 million output tokens per day - a realistic number for a production summarization or chat product — you're looking at:
- GPT-5.5: ~$4,500/month
- Gemini 3.1 Pro: ~$1,800–$2,250/month
That's $2,000 - $2,700 saved every month. At any meaningful scale, the cost difference alone can justify a model switch even if GPT-5.5 performs slightly better on your task.
For latency, in our direct tests on Eden AI, GPT-5.5 was faster across the board - including on complex, multi-step prompts where you'd expect more processing time. This is worth noting because it flips the conventional assumption that a cheaper model is faster.
Gemini 3.1 Pro's latency was noticeably behind on structured reasoning and instruction-following tasks in particular.
For user-facing applications where response speed affects experience, GPT-5.5 holds both the quality and speed advantage. Gemini's cost savings are real, but if latency is a priority alongside quality, the case for GPT-5.5 gets stronger - you're not just paying for better outputs, you're paying for faster ones too.
Using GPT-5.5 and Gemini 3.1 Pro in one platform
Testing two flagship models shouldn't mean managing two separate API keys, two billing accounts, and two sets of documentation. That'swhere most teams lose time: not in the AI work itself, but in the overhead around it.
Eden AI solves this by giving you access to both GPT-5.5 and Gemini 3.1 Pro through a single API. You can run the same prompt across both models in seconds, compare outputs side by side, and switch between them without touching your integration. All the tests in this article were run exactly this way.
In practice, this matters more than it sounds. The best teams don't pick one model and commit to it forever - they route tasks to the right model depending on what's needed. Eden AI makes that kind of switching frictionless, whether you're exploring in the playground or running it in production.




