
Résumez cet article avec :
- LiteLLM est une LLM gateway open source et un SDK Python qui permet aux équipes d'appeler 100+ fournisseurs de LLM via une interface compatible OpenAI.
- Le router prend cette décision selon des règles comme le coût , la latence , la qualité , le type de tâche ou la disponibilité du fournisseur .
- Dans certains benchmarks, le LLM routing peut réduire les coûts LLM jusqu'à 85 %, tout en conservant une grande partie de la qualité des modèles les plus performants.
- Un LLM router permet aux équipes de contrôler leurs coûts , d'améliorer la fiabilité, d'ajouter des fallbacks et de changer de fournisseur sans réécrire la logique applicative.
- Les tarifs publics ne sont pas entièrement self-serve pour tous les types de déploiement, mais la page pricing de Kong mentionne des fonctionnalités API et IA comme AI Gateway, le token rate limiting, le caching sémantique et les contrôles de coûts.
Gérer plusieurs fournisseurs de LLM devient vite complexe et coûteux. Chaque modèle a ses propres tarifs, niveaux de latence, limites de contexte, limites de débit, modes d’échec et niveaux de qualité de sortie. Un modèle performant pour la synthèse de texte peut être trop lent pour un chatbot, trop cher pour l’extraction de données ou peu fiable pour générer des sorties structurées.
Quand une équipe dépasse l’usage d’un seul modèle, elle a besoin d’une infrastructure capable de choisir automatiquement le bon fournisseur pour chaque requête, sans ajouter de logique personnalisée à plusieurs endroits du code.
C’est le rôle des LLM routers. Dans cet article, nous comparons les meilleurs LLM routers en 2026, des outils open source aux plateformes managées, en passant par les AI gateways avec fonctionnalités de routage. Vous trouverez aussi les principaux critères à prendre en compte pour choisir la solution la plus adaptée à votre stack technique.
Qu’est-ce qu’un LLM Router et pourquoi est-ce important en 2026 ?
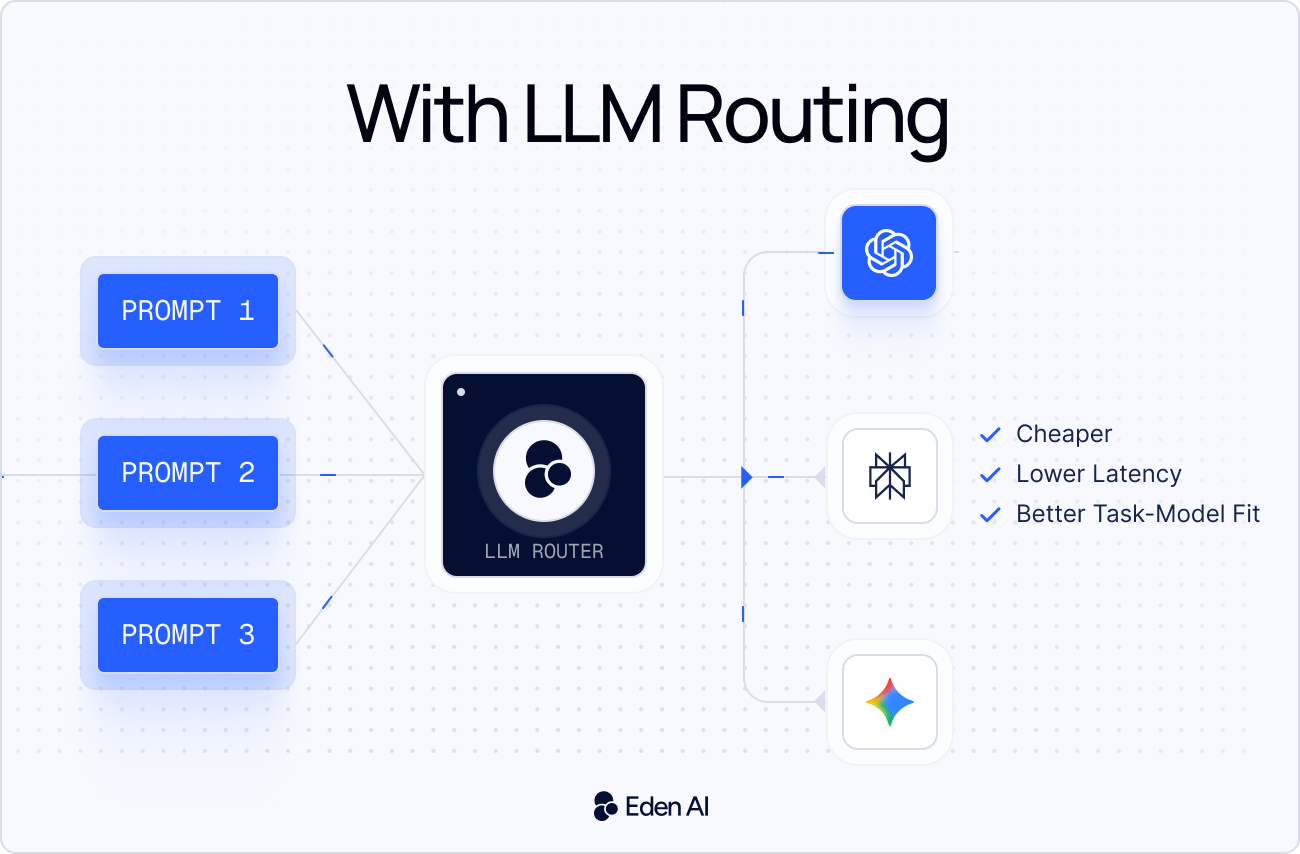
Un LLM router est une couche placée entre votre application et plusieurs modèles de langage. Son rôle est simple : envoyer chaque requête vers le modèle le plus adapté.
Par exemple, une tâche de classification basique peut être envoyée vers un modèle plus rapide et moins coûteux. À l’inverse, une requête complexe de raisonnement, de code ou à fort enjeu peut être dirigée vers un modèle plus puissant. Le router prend cette décision selon des règles comme le coût, la latence, la qualité, le type de tâche ou la disponibilité du fournisseur.
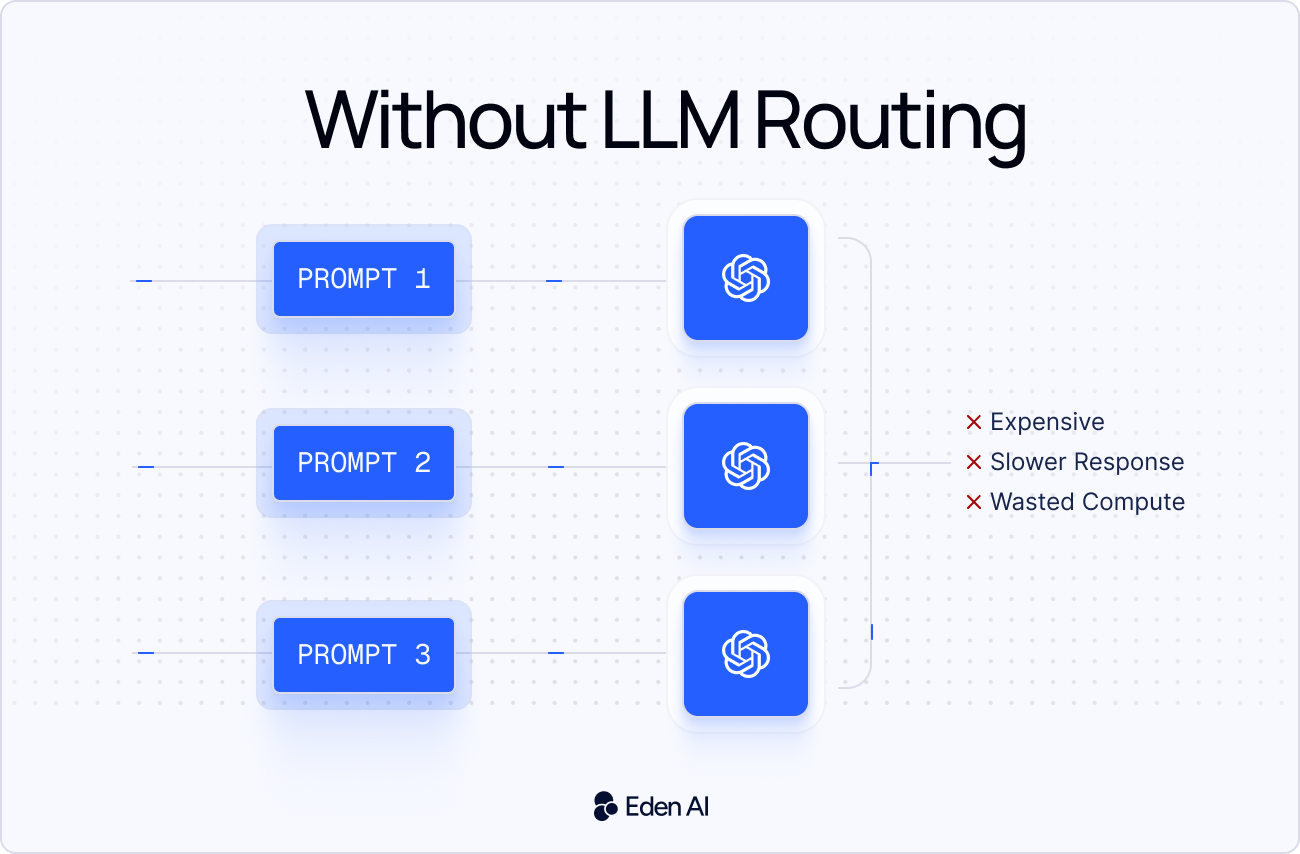
Cette approche devient essentielle, car la plupart des équipes IA ne s’appuient plus sur un seul modèle. Elles utilisent OpenAI, Anthropic, Google, Mistral, des modèles open source ou des fournisseurs spécialisés selon les cas d’usage. Sans routage, les équipes envoient souvent des tâches simples vers des modèles coûteux et paient plus que nécessaire.
Dans certains benchmarks, le LLM routing peut réduire les coûts LLM jusqu’à 85 %, tout en conservant une grande partie de la qualité des modèles les plus performants. Les économies réelles dépendent toutefois du workload, des prompts et de la stratégie de routage utilisée.
En 2026, le routage LLM devient encore plus important, car l’écosystème des modèles est de plus en plus fragmenté. Les prix changent, la latence varie et de nouveaux modèles apparaissent en permanence. Un LLM router permet aux équipes de contrôler leurs coûts, d’améliorer la fiabilité, d’ajouter des fallbacks et de changer de fournisseur sans réécrire la logique applicative.
Les 8 meilleurs LLM Routers en 2026
Eden AI
Eden AI est une AI gateway qui permet aux équipes d’accéder, de router et de monitorer des LLM, mais aussi des modèles d’IA spécialisés comme la transcription audio, la modération d’images, l’OCR, la traduction ou le parsing de documents, via une API unifiée.
Fonctionnalités clés
- Routage LLM compatible OpenAI : Eden AI permet d’utiliser plusieurs modèles de langage via une interface compatible avec les standards OpenAI, ce qui facilite l’intégration et le changement de fournisseur.
- Accès unifié aux LLM et aux modèles IA spécialisés : Eden AI prend en charge 500+ LLM et modèles d’IA, couvrant la génération de texte, l’OCR, le speech-to-text, le text-to-speech, la traduction, la vision par ordinateur et l’analyse de documents.
- Routage et fallbacks : Les équipes peuvent router les requêtes selon le coût, la performance ou la région, avec des fallbacks intégrés pour améliorer la fiabilité lorsqu’un fournisseur est lent, indisponible ou trop coûteux.
- Comparaison des fournisseurs : La plateforme inclut des outils pour comparer les modèles selon leur précision, leur latence et leur prix, ce qui aide les équipes à choisir les bons fournisseurs pour des workloads en production.
- Contrôle régional et conformité : Eden AI permet de sélectionner les régions d’hébergement, ce qui peut aider à répondre aux exigences du RGPD et à d’autres contraintes de protection des données en Europe.
Tarifs
Eden AI fonctionne avec un modèle pay-as-you-go basé sur une gateway, avec 5,5 % de frais de plateforme ajoutés à l’usage des fournisseurs. Eden AI propose aussi un plan Enterprise avec des fonctionnalités avancées pour les équipes ayant un volume élevé d’utilisation de modèles IA.
Limites
Eden AI est davantage une API managée qu’un router open source ou self-hosted. La solution peut donc être moins adaptée aux équipes qui veulent un contrôle total sur la couche de routage ou qui souhaitent tout exécuter dans leur propre infrastructure.
Idéal pour
Eden AI est particulièrement adapté aux équipes techniques qui veulent une API managée unique pour accéder à des LLM, des modèles IA spécialisés, des fallbacks fournisseurs, de l’optimisation des coûts et des contrôles liés à la confidentialité des données en Europe.
LiteLLM
LiteLLM est une LLM gateway open source et un SDK Python qui permet aux équipes d’appeler 100+ fournisseurs de LLM via une interface compatible OpenAI.
Fonctionnalités clés
- Large prise en charge des fournisseurs : LiteLLM prend en charge 100+ fournisseurs, dont OpenAI, Anthropic, Azure, Vertex AI, Bedrock, Cohere, Hugging Face, SageMaker, vLLM et NVIDIA NIM.
- Proxy compatible OpenAI : Les équipes peuvent exposer un endpoint API unique et appeler différents fournisseurs avec un format commun de type OpenAI. Cela réduit le travail d’intégration spécifique à chaque fournisseur.
- Routage, fallbacks et load balancing : Le proxy prend en charge des fonctionnalités de production comme les retries, le load balancing, les fallbacks, le suivi des coûts, les guardrails et les logs.
- Contrôle des dépenses et des accès: LiteLLM inclut des clés virtuelles, des budgets, des limites de débit, de la gestion d’équipes et du cost tracking. Ces fonctionnalités sont utiles pour les équipes platform qui gèrent plusieurs applications IA en interne.
Tarifs
Le cœur de LiteLLM est open source, ce qui permet aux équipes de le self-hoster sans payer de frais de plateforme. Les principaux coûts viennent de l’infrastructure, des opérations et de l’usage des fournisseurs de modèles. LiteLLM propose aussi un plan Enterprise, avec un pricing basé sur l’usage et défini sur devis.
Limites
LiteLLM est puissant, mais il demande une vraie ownership technique. Les équipes doivent déployer, sécuriser, monitorer, mettre à jour et opérer le proxy elles-mêmes, sauf si elles passent par une offre Enterprise ou managée. Il est donc moins plug-and-play qu’une plateforme de routage LLM entièrement managée.
Idéal pour
LiteLLM est idéal pour les équipes engineering qui veulent une LLM gateway open source et self-hostable, avec une large compatibilité fournisseurs, un routage compatible OpenAI et de solides contrôles internes des coûts.
Portkey
Portkey est une AI gateway et un control plane permettant de router, observer, sécuriser et gouverner le trafic LLM entre plusieurs fournisseurs.
Fonctionnalités clés
- AI gateway multi-fournisseurs : Portkey permet le routage à travers un large catalogue de modèles de langage, vision, audio et image via une couche gateway unifiée. Sa gateway open source indique prendre en charge 1 600+ modèles, avec retries, fallbacks, load balancing et routage conditionnel.
- Observabilité et suivi des coûts : Portkey fournit des logs de requêtes, des métriques de latence, du cost tracking et des contrôles budgétaires. La plateforme maintient aussi des données de pricing sur les modèles supportés, ce qui aide les équipes platform à suivre les dépenses par modèle, fournisseur, équipe ou application.
- Gouvernance et sécurité: La plateforme inclut des fonctionnalités Enterprise comme le contrôle d’accès basé sur les rôles, les audit logs, les guardrails et des contrôles orientés conformité pour les organisations qui gèrent l’usage de l’IA à grande échelle.
- Gateway open source : La gateway de Portkey est open source, ce qui en fait une option pertinente pour les équipes qui veulent plus de contrôle sur le déploiement, tout en utilisant l’écosystème Portkey pour la gestion de l’IA en production.
Tarifs
Portkey propose une option gratuite et open source pour les équipes qui souhaitent self-hoster la gateway, avec des coûts d’infrastructure et d’usage fournisseur facturés séparément. Sa plateforme managée suit un modèle basé sur l’usage, avec un free tier pour le développement et les tests. Les plans Enterprise sont disponibles sur devis et incluent des options avancées de gouvernance, d’audit logging, de support et de déploiement.
Limites
Portkey est plus large qu’un simple LLM router. Les équipes qui ont seulement besoin d’un changement léger de fournisseur peuvent trouver ses fonctionnalités d’observabilité, de gouvernance, de gestion de prompts et de sécurité plus avancées que nécessaire.
La solution demande aussi des décisions opérationnelles dès le départ. Les équipes doivent choisir entre self-hoster la gateway, utiliser la plateforme managée ou adopter des options de déploiement Enterprise. Cette flexibilité est utile, mais elle ajoute plus d’effort d’évaluation qu’un router managé plus simple.
Idéal pour
Portkey est idéal pour les équipes engineering et platform qui ont besoin d’un routage LLM prêt pour la production, avec une forte observabilité, de la gouvernance, du suivi des coûts et des contrôles multi-équipes.
Bifrost
Bifrost est une AI gateway open source, développée en Go par Maxim AI, qui fournit une API unique compatible OpenAI pour router les requêtes entre plusieurs fournisseurs de LLM.
Fonctionnalités clés
- Gateway compatible OpenAI : Bifrost permet aux équipes de se connecter à plusieurs fournisseurs d’IA via une API cohérente, ce qui réduit le travail d’intégration spécifique à chaque fournisseur et facilite le changement de modèle.
- Routage fournisseur et failover : La solution inclut du routage, des fallbacks automatiques et du load balancing. Elle est donc utile pour les applications où les interruptions fournisseur, les limites de débit ou les pics de latence peuvent affecter la fiabilité en production.
- Architecture haute performance : Bifrost est développé en Go et se positionne autour d’un trafic LLM à faible latence et haut débit. Les ressources de Maxim le présentent comme une solution conçue pour des workloads IA de production, plutôt que pour une simple expérimentation légère.
- Observabilité et contrôle des coûts : La plateforme inclut du monitoring des requêtes, de la télémétrie, le support d’OpenTelemetry, du cost tracking, des budgets et des intégrations avec les outils d’observabilité de Maxim AI.
Tarifs
Bifrost dispose d’une version open source que les équipes peuvent self-hoster, sans markup de plateforme sur l’usage des modèles. Les principaux coûts viennent de l’infrastructure, de la maintenance et des factures des fournisseurs sous-jacents. Bifrost propose aussi un plan Enterprise pour les déploiements de production plus avancés.
Limites
Bifrost convient bien aux équipes qui veulent opérer leur propre gateway, mais cela implique aussi une ownership engineering sur le déploiement, les mises à jour, la sécurité et le monitoring. La solution est donc moins plug-and-play qu’un router entièrement managé.
Bifrost est aussi principalement centré sur l’infrastructure de gateway LLM. Si votre équipe a besoin d’une API unique pour les LLM, mais aussi pour l’OCR, le speech-to-text, la traduction, l’analyse d’images ou le parsing de documents, il faudra probablement le combiner avec d’autres briques d’infrastructure IA.
Idéal pour
Bifrost est idéal pour les équipes engineering qui veulent une LLM gateway self-hosted et haute performance, avec routage, failover, observabilité et options de déploiement Enterprise.
Cloudflare AI Gateway
Cloudflare AI Gateway est une gateway managée qui permet de monitorer, mettre en cache, limiter le débit et router les requêtes IA entre plusieurs fournisseurs depuis le réseau edge de Cloudflare.
Fonctionnalités clés
- Gateway multi-fournisseurs : Cloudflare AI Gateway donne aux équipes une couche de contrôle unique pour gérer le trafic IA entre les fournisseurs supportés, avec la gestion des requêtes, les retries, les fallbacks et le fallback de modèles au niveau de la gateway.
- Observabilité et logs : La gateway fournit des analytics, des logs, du suivi des coûts, des métadonnées personnalisées et le support d’OpenTelemetry. Ces fonctionnalités aident les équipes engineering à comprendre la latence, l’usage, les erreurs et les dépenses sur leurs applications IA.
- Caching et rate limiting :Cloudflare peut mettre en cache les réponses IA identiques et les servir directement depuis son cache. Cela réduit les appels répétés aux fournisseurs et améliore les temps de réponse pour les workloads compatibles avec le caching.
- Routage dynamique et contrôles de sécurité : AI Gateway inclut du routage dynamique selon les segments utilisateurs, la géographie, l’analyse de contenu ou les tests A/B. La solution propose aussi des fonctionnalités de DLP et de guardrails pour les équipes qui veulent mieux contrôler les données sensibles et les sorties IA.
Tarifs
Cloudflare AI Gateway est disponible sur tous les plans Cloudflare. Ses fonctionnalités principales sont actuellement gratuites, notamment les analytics du dashboard, le caching et le rate limiting. Les logs persistants sont aussi disponibles, mais les limites de stockage varient selon le plan : Workers Free inclut 100 000 logs sur l’ensemble des gateways, tandis que Workers Paid inclut 10 millions de logs par gateway.
Limites
Les équipes qui ne sont pas déjà dans l’écosystème Cloudflare peuvent avoir besoin d’une configuration supplémentaire, ou préférer un router moins lié à une plateforme d’infrastructure plus large.
Cloudflare AI Gateway est aussi davantage une couche de contrôle et d’observabilité du trafic IA qu’une marketplace complète de modèles IA. Les équipes doivent toujours gérer leurs comptes fournisseurs, le choix des modèles et l’évaluation au niveau applicatif, sauf si elles l’associent à d’autres outils.
Idéal pour
Cloudflare AI Gateway est idéal pour les équipes qui veulent une couche managée de contrôle du trafic IA, avec observabilité, caching et routage, proche de leur infrastructure Cloudflare existante.
OpenRouter
OpenRouter est une marketplace LLM managée et une API de routage qui donne aux développeurs accès à des centaines de modèles via un endpoint unique compatible OpenAI.
Fonctionnalités clés
- Large catalogue de modèles : OpenRouter donne accès à 400+ modèles IA, notamment des modèles d’OpenAI, Anthropic, Google, Meta, Mistral, DeepSeek, xAI et d’autres fournisseurs. C’est utile pour les équipes qui veulent tester ou changer de modèle sans créer des intégrations séparées pour chaque fournisseur.
- API compatible OpenAI : OpenRouter fonctionne comme une couche API facile à intégrer dans de nombreuses configurations existantes basées sur les SDK OpenAI. Dans la plupart des cas, les équipes peuvent modifier l’URL de base, la clé API et le nom du modèle, plutôt que de réécrire leur intégration LLM.
- Routage fournisseur et fallbacks : OpenRouter peut router les requêtes vers le meilleur fournisseur disponible pour un modèle donné, répartir la charge entre plusieurs fournisseurs et essayer automatiquement des modèles de fallback lorsque le modèle ou fournisseur principal est indisponible, rate-limité ou bloqué.
- Auto routing : L’option
openrouter/autoutilise un méta-modèle pour router les prompts vers l’un de plusieurs modèles selon la qualité de sortie attendue. La réponse est facturée au tarif du modèle réellement utilisé.
Tarifs
OpenRouter utilise un modèle pay-as-you-go. Les utilisateurs achètent des crédits et paient le prix par token affiché pour chaque modèle, sans markup sur le prix fournisseur des modèles. OpenRouter facture 5,5 % de frais lors de l’achat de crédits, avec un minimum de 0,80 $.
Limites
OpenRouter est une plateforme managée, pas un router self-hosted. Les équipes qui veulent exécuter toute la couche de routage dans leur propre infrastructure peuvent préférer une gateway open source comme LiteLLM ou Bifrost.
OpenRouter est aussi principalement centré sur l’accès aux LLM et aux modèles. Il est solide pour comparer, router et payer de nombreux modèles depuis un seul endroit, mais les équipes qui ont besoin de workflows IA plus larges, d’OCR, de speech-to-text, de traduction ou de parsing de documents auront probablement besoin d’une infrastructure complémentaire.
Idéal pour
OpenRouter est idéal pour les développeurs et équipes IA qui veulent accéder rapidement à de nombreux LLM, changer facilement de fournisseur, utiliser du fallback routing et expérimenter avec différents modèles en pay-as-you-go via une seule API.
TrueFoundry AI Gateway
TrueFoundry AI Gateway est une AI gateway d’entreprise placée entre les applications et les fournisseurs de LLM. Elle offre aux équipes une couche unifiée pour le routage, la gouvernance, l’observabilité et le contrôle des accès.
Fonctionnalités clés
- Accès unifié à 1000+ LLM : TrueFoundry AI Gateway prend en charge 1000+ LLM via plusieurs fournisseurs, avec une interface unique pour les modèles externes, les modèles self-hosted et les services IA en production.
- Routage et load balancing : La gateway prend en charge les politiques de routage, le load balancing et le failover entre les modèles et les fournisseurs. Son gateway plane est présenté comme stateless, Kubernetes-native et conçu pour évaluer le routage et les guardrails en mémoire sur le hot path.
- Gouvernance et sécurité : TrueFoundry inclut une authentification centralisée, du contrôle d’accès, de l’application de politiques, des limites de débit, des budgets de tokens et des guardrails. Ces fonctionnalités sont pertinentes pour les entreprises qui doivent gérer l’usage de l’IA entre plusieurs équipes.
- Observabilité et gestion des coûts : La plateforme fournit du monitoring, des logs, du suivi d’usage, de la visibilité sur les performances et des contrôles budgétaires. Cela aide les équipes platform à comprendre la fiabilité, la latence et les dépenses sur leurs applications IA.
Tarifs
Le pricing de TrueFoundry AI Gateway dépend du déploiement et de l’usage. Les informations publiques mentionnent une option d’essai ou de démarrage, puis un markup sur les dépenses cloud, tandis que les plans Enterprise sont proposés sur devis.
Limites
TrueFoundry est conçu pour l’infrastructure IA d’entreprise. Il peut donc être plus lourd que nécessaire pour les équipes qui veulent seulement un changement simple de modèle ou un proxy compatible OpenAI léger. Son meilleur cas d’usage concerne les organisations qui ont déjà besoin de gouvernance, de déploiement Kubernetes-native, d’observabilité et de contrôles multi-équipes.
Le pricing est aussi moins transparent que celui des outils purement pay-as-you-go. Les équipes engineering devront probablement passer par une discussion commerciale pour estimer le coût total à l’échelle de la production.
Idéal pour
TrueFoundry AI Gateway est idéal pour les équipes platform en entreprise qui ont besoin d’un routage LLM gouverné et Kubernetes-native, couvrant à la fois les modèles externes et self-hosted.
Kong AI Gateway
Kong AI Gateway est une AI gateway d’entreprise basée sur la plateforme d’API management de Kong. Elle est conçue pour sécuriser, router, monitorer et gouverner le trafic LLM entre plusieurs fournisseurs.
Fonctionnalités clés
- Routage LLM et load balancing : Kong AI Gateway peut router les requêtes entre plusieurs modèles IA afin d’optimiser la vitesse, le coût et la fiabilité. Elle prend en charge des stratégies comme le round-robin, le routage vers la plus faible latence, le routage basé sur l’usage, le consistent hashing, le matching sémantique, les retries et les fallbacks.
- Plugins spécifiques à l’IA : Kong fournit des plugins orientés IA comme AI Proxy, AI Proxy Advanced, Prompt Guard, Prompt Template, Prompt Decorator, le caching sémantique et le rate limiting basé sur les tokens. Ces plugins aident les équipes à standardiser les appels LLM tout en ajoutant des contrôles sur les prompts, les réponses et l’usage.
- Sécurité et gouvernance : La principale force de Kong est la gouvernance API d’entreprise. Les équipes peuvent appliquer l’authentification, l’autorisation, les limites de débit, l’application de politiques, l’observabilité et le contrôle du trafic aux services IA, en utilisant la même plateforme que pour leurs API traditionnelles.
- Trafic API et IA dans une seule plateforme : Pour les entreprises qui utilisent déjà Kong, AI Gateway étend l’infrastructure existante aux LLM, aux ressources MCP et au trafic agent-to-agent, sans introduire une gateway séparée dédiée uniquement à l’IA.
Tarifs
Le pricing de Kong dépend de sa plateforme de connectivité API et IA, avec AI Gateway incluse dans son offre commerciale plus large. Les tarifs publics ne sont pas entièrement self-serve pour tous les types de déploiement, mais la page pricing de Kong mentionne des fonctionnalités API et IA comme AI Gateway, le token rate limiting, le caching sémantique et les contrôles de coûts. Les équipes peuvent commencer via Kong Konnect, tandis que les déploiements plus larges nécessitent généralement un plan commercial sur mesure.
Limites
Kong AI Gateway convient surtout aux équipes qui ont déjà besoin d’un API management d’entreprise. Si le seul besoin est un routage LLM léger, la solution peut sembler plus lourde que des outils spécialisés comme LiteLLM, Bifrost ou OpenRouter.
Kong AI Gateway n’est pas non plus principalement une marketplace de modèles ou un agrégateur de fournisseurs IA. Les équipes doivent toujours gérer leurs propres comptes fournisseurs, leurs choix de modèles, leurs credentials et leur processus d’évaluation.
Idéal pour
Kong AI Gateway est idéal pour les équipes platform et DevOps qui utilisent déjà Kong et veulent gouverner le trafic LLM avec la même couche de sécurité, de routage et d’observabilité que le reste de leur infrastructure API.
Comment choisir le bon LLM Router selon votre cas d’usage
Choisir le bon LLM router ne dépend pas seulement du nombre de modèles supportés. La meilleure option dépend surtout de la manière dont votre équipe veut gérer son infrastructure IA, contrôler ses coûts, répondre aux exigences de conformité et intégrer le router dans sa stack existante.
Commencez par le mode de déploiement
Si vous avez besoin d’une gateway self-hosted ou open source, LiteLLM est le choix par défaut le plus solide : flexible, largement adopté et compatible OpenAI. Bifrost est plus adapté si la faible latence et une infrastructure basée sur Go sont importantes pour votre équipe.
Si vous préférez éviter la charge opérationnelle liée au déploiement, à la sécurité, aux mises à jour et au monitoring, Eden AI, OpenRouter, Cloudflare AI Gateway et Portkey sont les principales options managées.
Ensuite, comparez les coûts
Eden AI est particulièrement pertinent lorsque l’optimisation des coûts doit couvrir à la fois les LLM et les modèles IA spécialisés : OCR, speech-to-text, traduction ou parsing de documents.
OpenRouter fonctionne bien pour l’accès pay-as-you-go à de nombreux LLM et l’expérimentation rapide entre modèles. LiteLLM convient davantage aux équipes qui veulent construire leurs propres contrôles de coûts en interne.
Prenez en compte la conformité et la gouvernance
Le bon choix dépend beaucoup de votre infrastructure existante. TrueFoundry AI Gateway convient aux équipes Enterprise qui ont besoin d’un déploiement Kubernetes-native, de contrôle d’accès, de budgets et de guardrails.
Kong AI Gateway est plus adapté aux entreprises qui utilisent déjà Kong pour l’API management. Portkey est solide pour l’observabilité, l’auditabilité et le contrôle multi-équipes.
Enfin, alignez le choix avec votre stack
Cloudflare AI Gateway est le choix naturel si votre application fonctionne déjà sur Cloudflare Workers. Kong convient aux entreprises API-first déjà équipées de Kong.
Eden AI couvre les équipes qui veulent une API managée unique pour le routage LLM, les modèles IA spécialisés, les fallbacks fournisseurs et les contrôles de confidentialité des données en Europe.
LLM Router vs AI Gateway : quelle différence ?
Un LLM router décide quel modèle ou fournisseur doit traiter une requête. Une AI gateway gère la manière dont les requêtes IA entrent, sortent et sont contrôlées dans votre infrastructure.
Dans la pratique, beaucoup d’outils font les deux. Un router peut choisir un modèle moins cher pour des prompts simples, réessayer avec un autre fournisseur en cas d’échec, ou sélectionner l’endpoint le plus rapide. Une AI gateway peut inclure cette même logique de routage, mais elle ajoute généralement des contrôles plus larges : authentification, logs, caching, application de politiques, suivi des coûts et observabilité.
La règle simple : utilisez le terme LLM router quand la question principale est “quel modèle doit répondre ?”. Utilisez AI gateway quand la question principale est “comment contrôler le trafic IA ?”.
Combien peut-on réellement économiser avec le routage LLM ?
Le routage LLM peut réduire les coûts de 30 % à 85 %, selon votre workload, votre mix de modèles et vos exigences de qualité. Les économies les plus importantes viennent généralement des applications où beaucoup de requêtes sont simples, répétitives ou peu risquées, tandis qu’une plus petite partie nécessite un raisonnement avancé.
Des recherches récentes sur le routage LLM rapportent des réductions de coûts de 40 % à 85 %, tout en conservant une qualité proche des modèles frontier. Les résultats varient toutefois selon les types de tâches.
La logique est simple : toutes les requêtes n’ont pas besoin de votre modèle le plus cher. Une classification courte, une réponse FAQ, une extraction d’entités ou une tâche de formatage peut souvent être traitée par un modèle moins coûteux. Les requêtes plus complexes, comme l’analyse juridique, la génération de code, le raisonnement multi-étapes ou les réponses client sensibles, peuvent rester routées vers un modèle plus puissant.
Par exemple, imaginons 1 million de requêtes par mois :
Si les 1 million de requêtes sont envoyées au modèle premium à 0,006 $ par requête, le coût mensuel est de 6 000 $. Avec le routage, le coût tombe à 1 020 $, soit une réduction de 83 % dans cet exemple hypothétique.
Le point clé n’est pas de choisir systématiquement le modèle le moins cher. Il s’agit de router chaque requête vers le modèle le moins coûteux capable de respecter le niveau de qualité attendu.
Avec Eden AI, les équipes peuvent router leurs requêtes entre plusieurs fournisseurs de LLM, comparer les coûts et les performances, ajouter des fallbacks et appliquer la même logique à des modèles IA spécialisés comme l’OCR, le speech-to-text, la traduction et le parsing de documents.
Conclusion
Le bon routeur LLM dépend de la façon dont votre équipe souhaite gérer son infrastructure IA. Si vous avez besoin d'un contrôle total, LiteLLM et Bifrost sont les meilleures options open-source. Si vous préférez une couche gérée qui couvre les LLMs, les modèles IA experts, les fallbacks et la confidentialité des données en Europe - sans overhead opérationnel - Eden AI est fait pour ça.
Essayez Eden AI gratuitement et commencez à router vos requêtes vers 500+ modèles en quelques minutes, sans infrastructure à gérer.

.jpg)
.png)

