
Summarize this article with:
- Unified access to LLMs and expert models: Eden AI supports 500+ LLMs and AI models, including generative AI, OCR, speech-to-text, text-to-speech, translation, vision, and document parsing models.
- Provider comparison: The platform includes tools to compare models on accuracy, latency, and price, which is useful when choosing between providers for production workloads.
- OpenAI-compatible gateway: Bifrost lets teams connect to multiple AI providers through one consistent API, which reduces provider-specific integration work and makes switching models easier.
- What does an LLM router do in a production AI application?
- Key criteria include task-specific accuracy, pricing per request, supported languages, API latency, and ease of integration.
Managing multiple LLM providers gets expensive fast. Each model has different pricing, latency, context limits, rate limits, failure modes, and output quality. What works well for summarization may be too slow for chat, too costly for extraction, or unreliable for structured outputs. As teams move beyond a single model, they need infrastructure that can choose the right provider for each request without adding custom logic everywhere in the codebase.
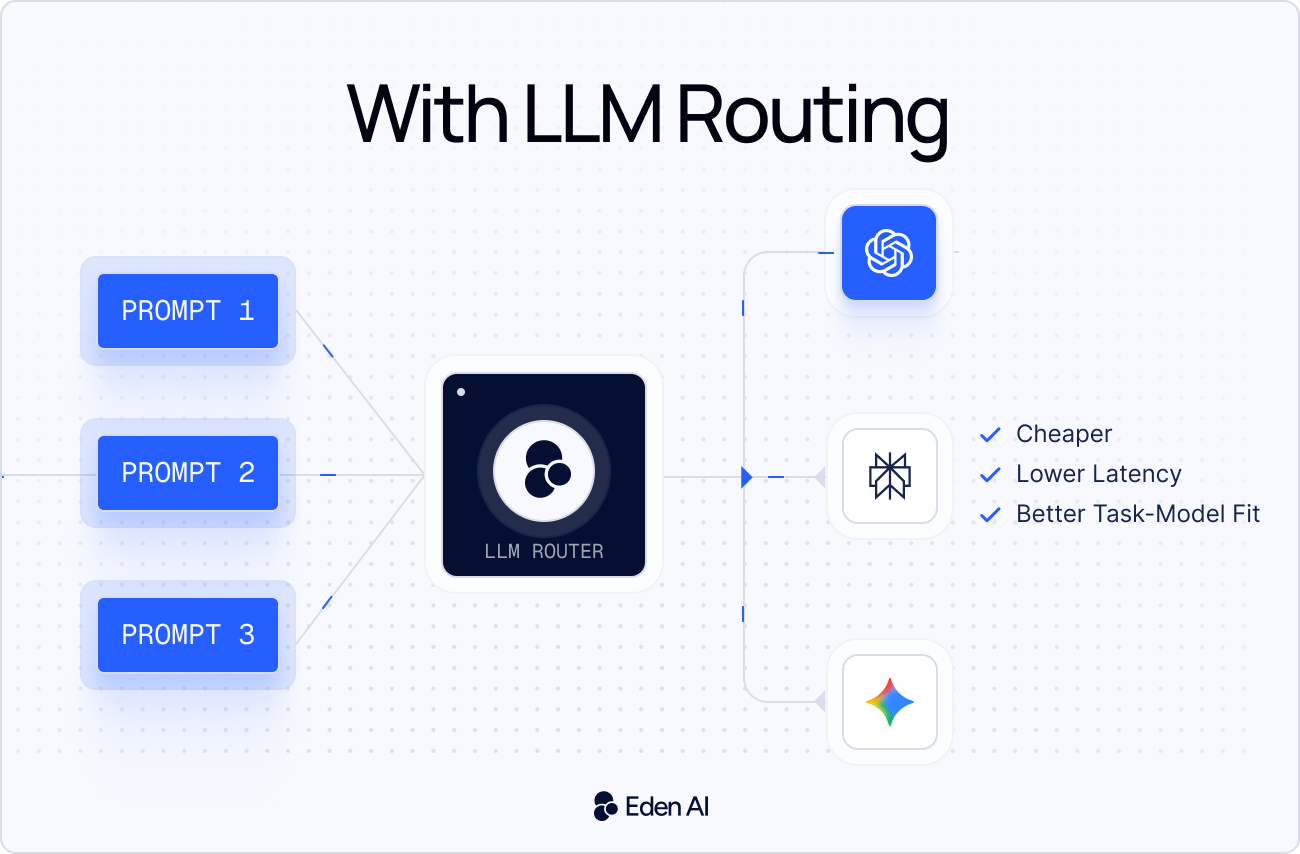
That is where LLM routers come in. An LLM router sits between your application and multiple model providers, then routes each request based on rules like cost, latency, quality, availability, region, or task type. Instead of hardcoding model choices, teams can centralize routing, fallbacks, monitoring, and optimization in one layer.
This article compares the best LLM routers in 2026, including open-source tools, managed platforms, AI gateways with routing features, and the key criteria engineers should use to choose one.
What Is an LLM Router and Why Does It Matter in 2026?
An LLM router is a layer between your application and multiple language models. Its job is simple: send each request to the model that fits best.
For example, a basic classification task can go to a cheaper, faster model. A complex reasoning, coding, or high-risk request can go to a stronger model. The router makes this decision based on rules such as cost, latency, quality, task type, or provider availability.
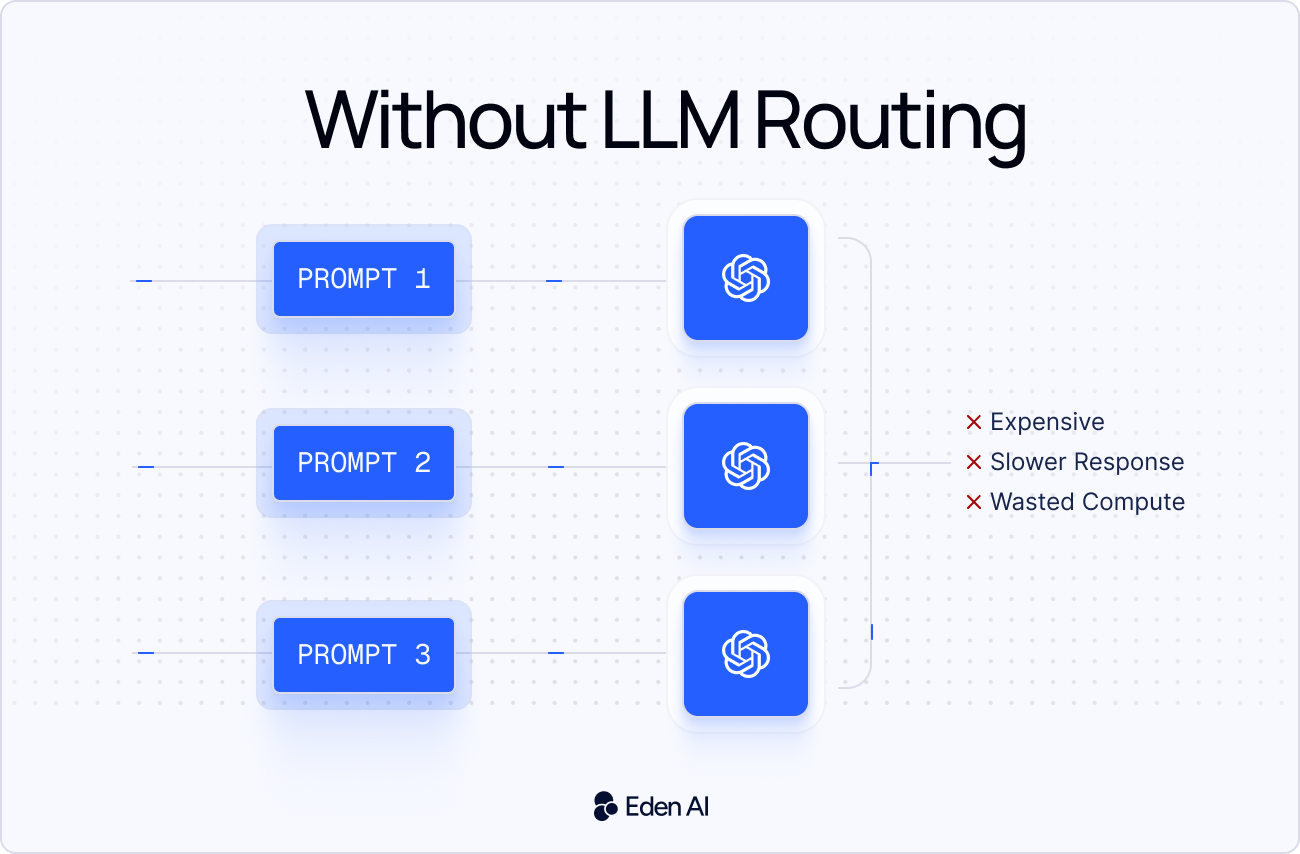
This matters because most AI teams no longer rely on a single model. They use OpenAI, Anthropic, Google, Mistral, open-source models, and specialized providers depending on the use case. Without routing, teams often send simple tasks to expensive models and pay more than they need to.
In some benchmarks, routing can reduce LLM costs by up to 85% while keeping most of the quality of stronger models. Actual savings depend on the workload, prompts, and routing strategy.
In 2026, LLM routing is becoming more important because the model landscape is fragmented. Prices change, latency varies, and new models appear constantly. A router gives teams a flexible way to control costs, improve reliability, add fallbacks, and switch providers without rewriting application logic.
The 8 Best LLM Routers in 2026
Eden AI
Eden AI is an AI gateway that lets teams access, route, and monitor both LLMs and specialized AI models like speech-to-text, image moderation, OCR, etc. through one unified API.
Key features
- OpenAI-compatible LLM routing
- Unified access to LLMs and expert models: Eden AI supports 500+ LLMs and AI models, including generative AI, OCR, speech-to-text, text-to-speech, translation, vision, and document parsing models.
- Routing and fallbacks: Teams can route requests by cost, performance, and region, with built-in fallbacks to improve reliability when a provider is slow, unavailable, or too expensive.
- Provider comparison: The platform includes tools to compare models on accuracy, latency, and price, which is useful when choosing between providers for production workloads.
- Regional control and compliance: Eden AI lets users select hosting regions, which can help with GDPR and other local data protection requirements in Europe.
Pricing
Eden AI uses a pay-as-you-go gateway model with a 5.5% platform fee on top of provider usage. Eden AI also offers an Enterprise plan with advanced features designed for teams with high-volume AI model usage.
Limitations
Eden AI is more an API than an open-source or self-hosted router, so it may not fit teams that need full control over the routing layer or want to run everything inside their own infrastructure.
Best for
Eden AI is best for engineering teams that want one managed API for LLMs, expert AI models, provider fallback, cost optimization, and European data privacy controls.
LiteLLM
LiteLLM is an open-source LLM gateway and Python SDK that lets teams call 100+ LLM providers through an OpenAI-compatible interface.
Key features
- Broad provider support: LiteLLM supports 100+ providers, including OpenAI, Anthropic, Azure, Vertex AI, Bedrock, Cohere, Hugging Face, SageMaker, vLLM, and NVIDIA NIM.
- OpenAI-compatible proxy: Teams can expose a single API endpoint and call different providers using a common OpenAI-style format, reducing provider-specific integration work.
- Routing, fallbacks, and load balancing: The proxy supports production gateway features such as retries, load balancing, fallbacks, cost tracking, guardrails, and logging.
- Spend and access controls: LiteLLM includes virtual keys, budgets, rate limits, team management, and cost tracking, which are useful for internal AI platform teams managing multiple applications.
Pricing
LiteLLM’s core project is open source, so teams can self-host it without paying a platform fee. The main costs are infrastructure, operations, and the underlying model provider usage. LiteLLM also offers an Enterprise plan with pricing based on usage and quoted directly for each team.
Limitations
LiteLLM is powerful, but it requires engineering ownership. Teams need to deploy, secure, monitor, upgrade, and operate the proxy themselves unless they use an enterprise or managed setup. That makes it less plug-and-play than a fully managed LLM routing platform.
Best for
LiteLLM is best for engineering teams that want an open-source, self-hostable LLM gateway with broad provider support, OpenAI-compatible routing, and strong internal cost controls.
Portkey
Portkey is an AI gateway and control plane for routing, observing, securing, and governing LLM traffic across multiple providers.
Key features
- Multi-provider AI gateway: Portkey supports routing across a large catalog of language, vision, audio, and image models through a unified gateway layer. Its open-source gateway describes support for 1,600+ models and includes retries, fallbacks, load balancing, and conditional routing.
- Observability and cost tracking: Portkey provides request logs, latency metrics, cost tracking, and budget controls. It also maintains model pricing data across supported providers, which helps platform teams monitor spend by model, provider, team, or application.
- Governance and security controls: The platform includes enterprise features such as role-based access control, audit logs, guardrails, and compliance-oriented controls for teams managing AI usage across an organization.
- Open-source gateway option: Portkey’s gateway is open source, which makes it relevant for teams that want more control over deployment while still using Portkey’s broader ecosystem for production AI management.
Pricing
Portkey offers a free/open-source gateway option for teams that want to self-host, with infrastructure and provider usage billed separately. Its managed platform follows a usage-based model with a free tier for development and testing, while enterprise plans are quoted separately and include more advanced governance, audit logging, support, and deployment options.
Limitations
Portkey is broader than a simple LLM router. Teams that only need lightweight provider switching may find its observability, governance, prompt management, and security features more than they need.
It can also require operational decisions upfront. Teams need to choose between self-hosting the gateway, using the managed platform, or adopting enterprise deployment options. That flexibility is useful, but it adds more evaluation work than a basic managed router.
Best for
Portkey is best for engineering and platform teams that need production-grade LLM routing with strong observability, governance, cost tracking, and multi-team controls.
Bifrost
Bifrost is an open-source, Go-based AI gateway from Maxim AI that provides a single OpenAI-compatible API for routing requests across multiple LLM providers.
Key features
- OpenAI-compatible gateway: Bifrost lets teams connect to multiple AI providers through one consistent API, which reduces provider-specific integration work and makes switching models easier.
- Provider routing and failover: It includes routing, automatic fallbacks, and load balancing, making it useful for applications where provider downtime, rate limits, or latency spikes can affect production reliability.
- High-performance architecture: Bifrost is built in Go and positions itself around low-latency, high-throughput LLM traffic. Maxim’s materials describe it as designed for production-scale AI workloads rather than lightweight experimentation.
- Observability and cost controls: The platform includes request monitoring, telemetry, OpenTelemetry support, cost tracking, budgeting, and integration with Maxim AI’s observability tools.
Pricing
Bifrost has an open-source version that teams can self-host, with no platform markup on model usage. The main costs are infrastructure, maintenance, and the underlying provider bills. Bifrost also offers an Enterprise plan for larger production deployments.
Limitations
Bifrost is a strong fit for teams that want to operate their own gateway, but that also means they need engineering ownership for deployment, upgrades, security, and monitoring. It is less plug-and-play than a fully managed router.
It is also focused mainly on LLM gateway infrastructure. If your team needs one API for LLMs plus OCR, speech-to-text, translation, image analysis, or document parsing, you may need to combine Bifrost with other AI infrastructure.
Best for
Bifrost is best for engineering teams that need a self-hosted, high-performance LLM gateway with routing, failover, observability, and enterprise deployment options.
Cloudflare AI Gateway
Cloudflare AI Gateway is a managed gateway for monitoring, caching, rate limiting, and routing AI requests across multiple providers from Cloudflare’s edge network.
Key features
- Multi-provider gateway: Cloudflare AI Gateway gives teams one control layer for AI traffic across supported providers, with request handling, retries, fallbacks, and model fallback available at the gateway level.
- Observability and logging: The gateway provides analytics, logs, cost tracking, custom metadata, and OpenTelemetry support, which helps engineering teams understand latency, usage, errors, and spend across AI applications.
- Caching and rate limiting: Cloudflare can cache identical AI responses and serve them directly from its cache, reducing repeated provider calls and improving response times for cacheable workloads.
- Dynamic routing and safety controls: AI Gateway includes dynamic routing for flows based on user segments, geography, content analysis, or A/B testing. It also offers DLP and guardrails features for teams that need more control over sensitive data and AI outputs.
Pricing
Cloudflare AI Gateway is available on all Cloudflare plans. Its core features are currently free, including dashboard analytics, caching, and rate limiting. Persistent logs are also available, but storage limits vary by plan: Workers Free includes 100,000 logs across all gateways, while Workers Paid includes 10 million logs per gateway.
Limitations
Teams outside the Cloudflare ecosystem may need extra setup or may prefer a router that is less tied to a broader infrastructure platform.
It is also more of an AI traffic control and observability layer than a full AI model marketplace. Teams still need to manage provider accounts, model selection, and application-level evaluation unless they pair it with additional tooling.
Best for
Cloudflare AI Gateway is best for teams that want managed AI traffic control, observability, caching, and routing close to their existing Cloudflare infrastructure.
OpenRouter
OpenRouter is a managed LLM marketplace and routing API that gives developers access to hundreds of models through a single OpenAI-compatible endpoint.
Key features
- Large model catalog: OpenRouter provides access to 400+ AI models, including models from OpenAI, Anthropic, Google, Meta, Mistral, DeepSeek, xAI, and other providers. This makes it useful for teams that want to test or switch models without creating separate provider integrations.
- OpenAI-compatible API: OpenRouter works as a drop-in API layer for many existing OpenAI SDK setups. In most cases, teams can change the base URL, API key, and model name rather than rewriting their LLM integration.
- Provider routing and fallbacks: OpenRouter can route requests to the best available provider for a selected model, load balance across providers, and automatically try fallback models when the primary model or provider is unavailable, rate-limited, or blocked.
- Auto routing: The openrouter/auto option uses a meta-model to route prompts to one of several models based on expected output quality. The response is billed at the rate of the model actually used.
Pricing
OpenRouter uses a pay-as-you-go model. Users buy credits and pay the posted per-token price of each model, with no markup on provider model pricing. OpenRouter charges a 5.5% fee when credits are purchased, with a $0.80 minimum fee.
Limitations
OpenRouter is a managed platform, not a self-hosted router. Teams that need to run the routing layer fully inside their own infrastructure may prefer an open-source gateway such as LiteLLM or Bifrost.
It is also mainly focused on LLM and model access. It is strong for comparing, routing, and paying for many models from one place, but teams that need broader AI workflows, OCR, speech-to-text, translation, or document parsing may need additional infrastructure.
Best for
OpenRouter is best for developers and AI teams that want fast access to many LLMs, simple provider switching, fallback routing, and pay-as-you-go model experimentation through one API.
TrueFoundry AI Gateway
TrueFoundry AI Gateway is an enterprise AI gateway that sits between applications and LLM providers, giving teams a unified layer for routing, governance, observability, and access control.
Key features
- Unified access to 1000+ LLMs: TrueFoundry AI Gateway supports 1000+ LLMs through multiple providers, giving teams one interface for external models, self-hosted models, and production AI services.
- Routing and load balancing: The gateway supports routing policies, load balancing, and failover across models and providers. Its gateway plane is described as stateless, Kubernetes-native, and designed to evaluate routing and guardrails in memory on the hot path.
- Governance and security controls: TrueFoundry includes centralized authentication, access control, policy enforcement, rate limits, token budgeting, and guardrails. This makes it relevant for enterprises that need to manage AI usage across multiple teams.
- Observability and cost management: The platform provides monitoring, logs, usage tracking, performance visibility, and budget controls, helping platform teams understand reliability, latency, and spend across AI applications.
Pricing
TrueFoundry’s AI Gateway pricing depends on deployment and usage. Public pricing references a trial/self-start option, followed by a markup on cloud spend, while enterprise pricing is custom.
Limitations
TrueFoundry is built for enterprise AI infrastructure, so it may be heavier than needed for teams that only want lightweight model switching or a simple OpenAI-compatible proxy. Its strongest fit is for organizations that already need governance, Kubernetes-native deployment, observability, and multi-team controls.
Pricing is also less transparent than pure pay-as-you-go tools. Engineering teams will likely need a sales discussion to estimate total cost at production scale.
Best for
TrueFoundry AI Gateway is best for enterprise platform teams that need governed, Kubernetes-native LLM routing across external and self-hosted models.
Kong AI Gateway
Kong AI Gateway is an enterprise AI gateway built on Kong’s API management platform, designed to secure, route, monitor, and govern LLM traffic across providers.
Key features
- LLM routing and load balancing: Kong AI Gateway can route requests across AI models to optimize speed, cost, and reliability. It supports routing strategies such as round-robin, lowest-latency, usage-based routing, consistent hashing, semantic matching, retries, and fallbacks.
- AI-specific gateway plugins: Kong provides AI-focused plugins such as AI Proxy, AI Proxy Advanced, Prompt Guard, Prompt Template, Prompt Decorator, semantic caching, and token-based rate limiting. These help teams standardize LLM calls while adding controls around prompts, responses, and usage.
- Security and governance: Kong’s main strength is enterprise API governance. Teams can apply authentication, authorization, rate limits, policy enforcement, observability, and traffic controls to AI services using the same platform they use for traditional APIs.
- API and AI traffic in one platform: For companies already using Kong, AI Gateway extends existing infrastructure to LLMs, MCP resources, and agent-to-agent traffic instead of introducing a separate AI-specific gateway.
Pricing
Kong pricing is based on its API and AI connectivity platform, with AI Gateway included in Kong’s broader commercial offering. Public pricing is not fully self-serve for every deployment type, but Kong’s pricing page describes API and AI connectivity features such as AI Gateway, token rate limiting, semantic caching, and cost controls. Teams can start through Kong Konnect, while larger deployments usually require a custom commercial plan.
Limitations
Kong AI Gateway is best suited to teams that already need enterprise API management. If the only requirement is lightweight LLM routing, it may feel heavier than purpose-built tools such as LiteLLM, Bifrost, or OpenRouter.
It is also not primarily a model marketplace or AI provider aggregator. Teams still need to manage their own provider accounts, model choices, credentials, and evaluation process.
Best for
Kong AI Gateway is best for platform and DevOps teams that already use Kong and want to govern LLM traffic with the same security, routing, and observability layer as the rest of their API infrastructure.
How to Choose the Right LLM Router for Your Use Case
Choosing the right LLM router is not just about the number of supported models. The best option depends on how your team wants to manage AI infrastructure, control costs, meet compliance requirements, and fit the router into your existing stack.
Start with deployment
If you need a self-hosted or open-source gateway, LiteLLM is the strongest default: flexible, widely adopted, and OpenAI-compatible. Bifrost is a better fit if low latency and Go-based infrastructure matter. If you'd rather skip the ops overhead, Eden AI, OpenRouter, Cloudflare AI Gateway, and Portkey are the main managed options.
Next, consider cost
Eden AI is the strongest fit when cost optimization needs to cover both LLMs and specialized models - OCR, speech, translation, and document parsing. OpenRouter works well for pay-as-you-go model access and experimentation across many LLMs. LiteLLM suits teams that want to build cost controls internally.
Consider compliance and governance
The right choice depends on your infrastructure. TrueFoundry AI Gateway fits enterprise teams that need Kubernetes-native deployment, access control, budgets, and guardrails. Kong AI Gateway fits companies already using Kong for API management. Portkey is strong for observability, auditability, and multi-team control.
Finally, match your stack
Cloudflare AI Gateway is the natural pick if your app runs on Cloudflare Workers. Kong fits API-first enterprises already on Kong. Eden AI covers teams that want one managed API for LLM routing, expert AI models, provider fallback, and European data privacy.
LLM Router vs AI Gateway: Is There a Difference?
An LLM router decides which model or provider should handle a request. An AI gateway manages how AI requests enter, leave, and are controlled across your infrastructure.
Many tools are both. A router can choose a cheaper model for simple prompts, retry on another provider when one fails, or select the fastest endpoint. An AI gateway may include the same routing logic, but it usually adds broader controls such as authentication, logging, caching, policy enforcement, cost tracking, and observability.
Rule of thumb: use “LLM router” when the main question is which model should answer? Use “AI gateway” when the main question is how should AI traffic be controlled?
How Much Can LLM Routing Actually Save You?
LLM routing can reduce costs by 30-85%, depending on your workload, model mix, and quality requirements. The highest savings usually come from applications where many requests are simple, repetitive, or low-risk, while only a smaller share requires advanced reasoning. Recent routing research reports 40-85% cost reduction while keeping quality close to frontier-model baselines, but results vary by task type.
The logic is simple: not every request needs your most expensive model. A short classification, FAQ answer, entity extraction, or formatting task can often be handled by a cheaper model. More complex requests, such as legal analysis, code generation, multi-step reasoning, or sensitive customer-facing answers, can still be routed to a stronger model.
For example, imagine 1M requests/month:
If all 1M requests went to the premium model at $0.006/request, the monthly cost would be $6,000. With routing, the cost drops to $1,020, an 83% reduction in this hypothetical setup.
The key is not just choosing the cheapest model. It is routing each request to the least expensive model that can still meet the quality requirement.
With Eden AI, teams can route requests across multiple LLM providers, compare cost and performance, add fallbacks, and extend the same approach to expert AI models like OCR, speech, translation, and document parsing.
Conclusion
The right LLM router depends on how your team wants to manage AI infrastructure. If you need full control, LiteLLM and Bifrost are the strongest open-source options.If you want a managed layer that covers LLMs, expert AI models, fallbacks, and EU data privacy without the ops overhead, Eden AI is built for that. Try Eden AI for free and start routing requests across 500+ models in minutes - no infrastructure required.

.jpg)
.png)

