.png)
Résumez cet article avec :
- Gemini 3.5 Flash est un modèle plus léger de la famille Gemini 3.5 , développé par Google DeepMind et annoncé lors du Google I/O 2026 , le 19 mai 2026.
- Utiliser Gemini 3.5 Flash via Eden AI permet à votre équipe d'accéder au dernier modèle de Google aux côtés de 500+ autres modèles d'IA, via une seule API unifiée .
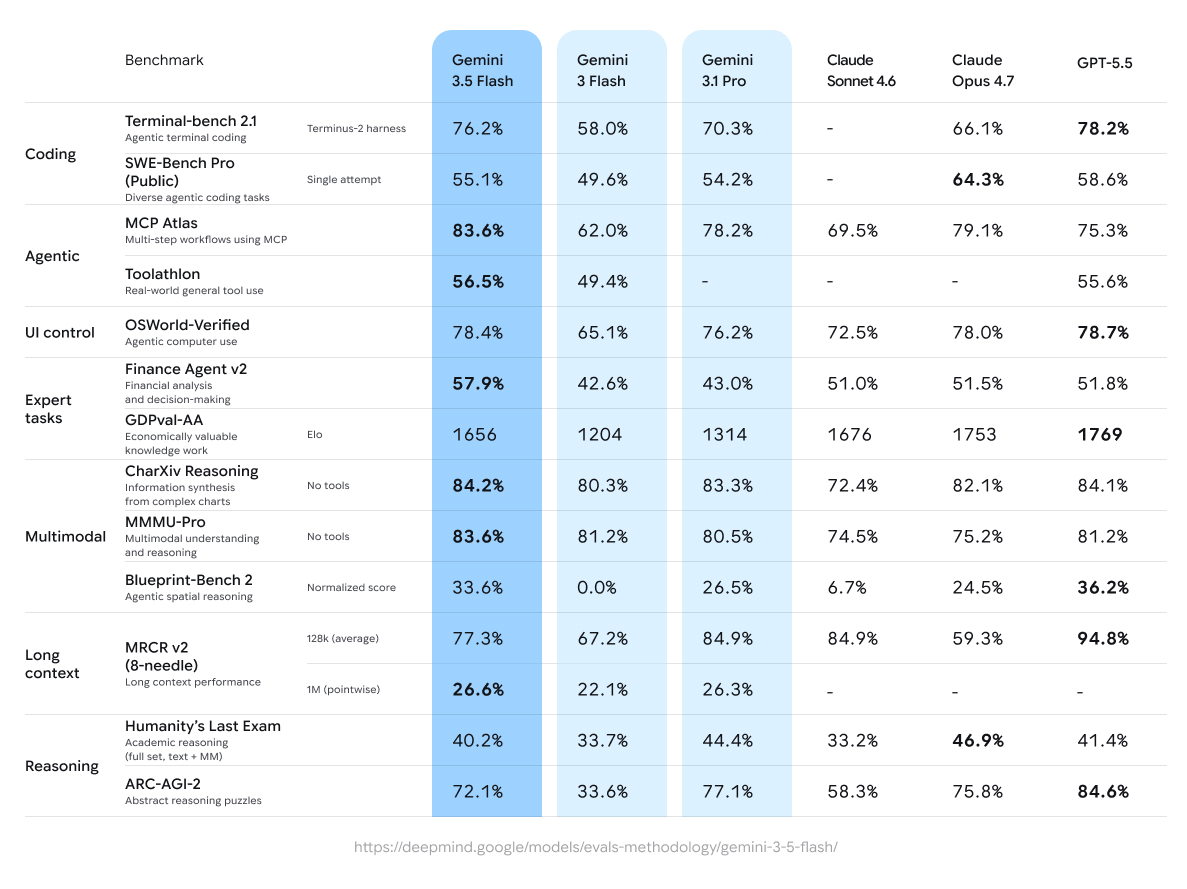
- Comparé à Gemini 3.1 Pro , il peut générer des tokens de sortie jusqu'à 4 fois plus rapidement , ce qui en fait un modèle particulièrement adapté aux applications où le temps de réponse est un critère important.
- À première vue, Gemini 3.5 Flash semble être le modèle le plus lent et le plus coûteux du test.
- Rapporté au nombre de tokens générés, Gemini 3.5 Flash s'est révélé être le modèle le plus rapide du test .
Annoncé par Google lors de l’I/O 2026, Gemini 3.5 Flash est le modèle le plus rapide et le plus rentable de la famille Gemini 3.5. Grâce à Eden AI, les développeurs peuvent l’utiliser facilement pour créer et tester des workflows agentiques, des assistants de code, des applications multimodales et d’autres cas d’usage sensibles à la latence, tout en gardant le contrôle sur leurs coûts.
Qu’est-ce que Gemini 3.5 Flash ?
Gemini 3.5 Flash est un modèle plus léger de la famille Gemini 3.5, développé par Google DeepMind et annoncé lors du Google I/O 2026, le 19 mai 2026.
Positionné aux côtés de Gemini 3.5 Pro, plus puissant, il est conçu pour les développeurs qui recherchent des réponses plus rapides, des coûts réduits et des capacités avancées. Le modèle prend en charge les entrées multimodales, notamment le texte, les images, l’audio et la vidéo, avec une fenêtre de contexte allant jusqu’à 1 048 576 tokens en entrée et 65 536 tokens en sortie.
La fonctionnalité Dynamic Thinking est activée par défaut, ce qui permet au modèle d’ajuster automatiquement sa puissance de calcul pour les tâches plus complexes. Sa date de coupure des connaissances est fixée à janvier 2026.
Qu’est-ce qui distingue Gemini 3.5 Flash ?
Gemini 3.5 Flash est conçu pour les équipes qui recherchent de bonnes performances IA sans ajouter de latence inutile ni augmenter les coûts.
Comparé à Gemini 3.1 Pro, il peut générer des tokens de sortie jusqu’à 4 fois plus rapidement, ce qui en fait un modèle particulièrement adapté aux applications où le temps de réponse est un critère important.
Pour les développeurs, sa principale valeur réside dans les workflows agentiques et les tâches de codage. Gemini 3.5 Flash peut notamment aider à gérer l’utilisation d’outils, le raisonnement en plusieurs étapes, la génération de code, le debugging et l’exécution automatisée de workflows.
Une différence clé réside dans le Dynamic Thinking, une fonctionnalité qui alloue automatiquement davantage de puissance de calcul lorsque la tâche est plus complexe. Cela permet de trouver un bon équilibre entre rapidité et qualité du raisonnement, sans obliger les développeurs à ajuster manuellement le comportement du modèle pour chaque requête.
Gemini 3.5 Flash est également proposé à un coût deux fois inférieur, voire plus bas, que certains modèles frontier comparables. Ses premiers déploiements en entreprise, notamment chez Shopify pour l’analyse des données marchands, Macquarie Bank pour le raisonnement sur documents, et Salesforce pour l’automatisation d’entreprise, montrent comment ce modèle peut être utilisé dans des cas d’usage en production.
Premier benchmark de Gemini 3.5 Flash face à GPT, Claude et Mistral
Nous avons testé une tâche de développement Python en conditions de production sur quatre modèles via Eden AI. L’objectif : générer une fonction Python avec type hints, filtrage par date et gestion des cas limites.
Voici le prompt utilisé :
“You are a senior backend developer. Write a Python function that:
- Takes a list of JSON objects representing invoices (fields: id, amount, currency, date, status)
- Filters only unpaid invoices from the last 30 days
- Returns a summary dict with: total_amount_due, count, oldest_unpaid_date
Include type hints and handle edge cases (empty list, missing fields).”
Résultats du benchmark :
À première vue, Gemini 3.5 Flash semble être le modèle le plus lent et le plus coûteux du test. Mais ce résultat doit être nuancé : il a généré 7,5 fois plus de contenu que GPT-4.1-mini. Rapporté au nombre de tokens générés, Gemini 3.5 Flash s’est révélé être le modèle le plus rapide du test.
Ce que les réponses ont révélé
Deux niveaux de qualité se sont clairement distingués.
Gemini 3.5 Flash et Claude Haiku 4.5 ont produit des réponses plus complètes, proches d’un usage en production.
Gemini est le seul modèle à avoir inclus un paramètre reference_date testable, un élément essentiel pour les tests unitaires sans avoir recours au mocking. Il a également proposé une gestion complète des fuseaux horaires en UTC et des types de retour structurés avec TypedDict.
Claude Haiku, de son côté, est le seul modèle à avoir utilisé Decimal pour garantir la précision des montants financiers, ainsi qu’une liste d’erreurs dans le résultat, utile pour améliorer l’observabilité dans des pipelines de production.
Mistral Small et GPT-4.1-mini ont généré un code strictement identique : correct, propre et minimal. Pour une tâche standard bien cadrée, les modèles les moins chers peuvent donc converger vers une réponse très similaire. À 0,0002 $ par appel, Mistral apparaît comme un choix pertinent pour les workloads à fort volume et faible complexité.
Au final, aucun modèle n’est universellement meilleur. Gemini 3.5 Flash et Claude Haiku ont chacun identifié des cas limites que l’autre n’a pas couverts. C’est précisément ce type de décision qu’Eden AI permet de prendre par cas d’usage, plutôt que par contrat fournisseur.
Pourquoi utiliser Gemini 3.5 Flash via Eden AI ?
Utiliser Gemini 3.5 Flash via Eden AI permet à votre équipe d’accéder au dernier modèle de Google aux côtés de 500+ autres modèles d’IA, via une seule API unifiée. Au lieu de développer et maintenir des intégrations séparées pour chaque fournisseur, vous pouvez tester, comparer et déployer plusieurs modèles depuis une interface cohérente.
Pour les workloads en production, Eden AI aide à réduire les risques opérationnels grâce à :
- Routage de secours : si Gemini 3.5 Flash est limité ou indisponible, Eden AI peut rediriger automatiquement la requête vers un modèle de fallback configuré, sans modification de code de votre côté.
- Comparaison côte à côte : exécutez le même prompt sur Gemini 3.5 Flash et plusieurs autres modèles en simultané, comme dans le benchmark ci-dessus. Vous pouvez comparer la qualité, la latence et le coût selon votre workload réel avant de faire un choix.
- Pas de vendor lock-in : passer d’un modèle à un autre sur Eden AI nécessite de changer un seul paramètre, sans reconstruire toute votre intégration.
- Facturation unifiée : une seule facture pour l’ensemble des fournisseurs, avec un suivi des coûts par modèle intégré.
- Options conformes au RGPD : lorsque votre cas d’usage l’exige, vous pouvez orienter vos requêtes vers des infrastructures européennes compatibles avec vos contraintes de conformité.

.jpg)
%20(1).png)

