.png)
Summarize this article with:
- Dynamic thinking is enabled by default, allowing the model to automatically adjust compute for more complex tasks.
- Side-by-side comparison: Run the same prompt through Gemini 3.5 Flash and three other models simultaneously, as we did above.
- Is Gemini 3.5 Flash available via API?
- Create a free Eden AI account, generate your API key, and test the feature in the playground before integrating it with the provided code examples.
- Eden AI aggregates multiple providers for this feature, enabling side-by-side accuracy, speed, and cost comparisons from the dashboard or via API.
Gemini 3.5 Flash is now available on Eden AI. Announced by Google at I/O 2026, it is the fastest and most cost-efficient model in the Gemini 3.5 family. Developers can use it through Eden AI to build and test agentic workflows, coding assistants, and other latency-sensitive applications while keeping costs under control.
What is Gemini 3.5 Flash?
Gemini 3.5 Flash is a lighter-weight model in the Gemini 3.5 family, developed by Google DeepMind and announced at Google I/O 2026 on May 19, 2026.
Positioned alongside the more powerful Gemini 3.5 Pro, it is designed for developers who need faster responses and lower costs without giving up advanced capabilities. The model supports multimodal inputs, including text, images, audio, and video, with a context window of 1,048,576 input tokens and 65,536 output tokens.
Dynamic thinking is enabled by default, allowing the model to automatically adjust compute for more complex tasks. Its knowledge cutoff is January 2026.
What makes Gemini 3.5 Flash stand out?
Gemini 3.5 Flash is designed for teams that need strong model performance without adding unnecessary latency or cost. Compared with Gemini 3.1 Pro, it delivers output tokens up to 4x faster, making it well-suited for applications where response time matters.
For developers, the main value is in agentic and coding workflows. Gemini 3.5 Flash can support tasks such as tool use, multi-step reasoning, code generation, debugging, and automated workflow execution.
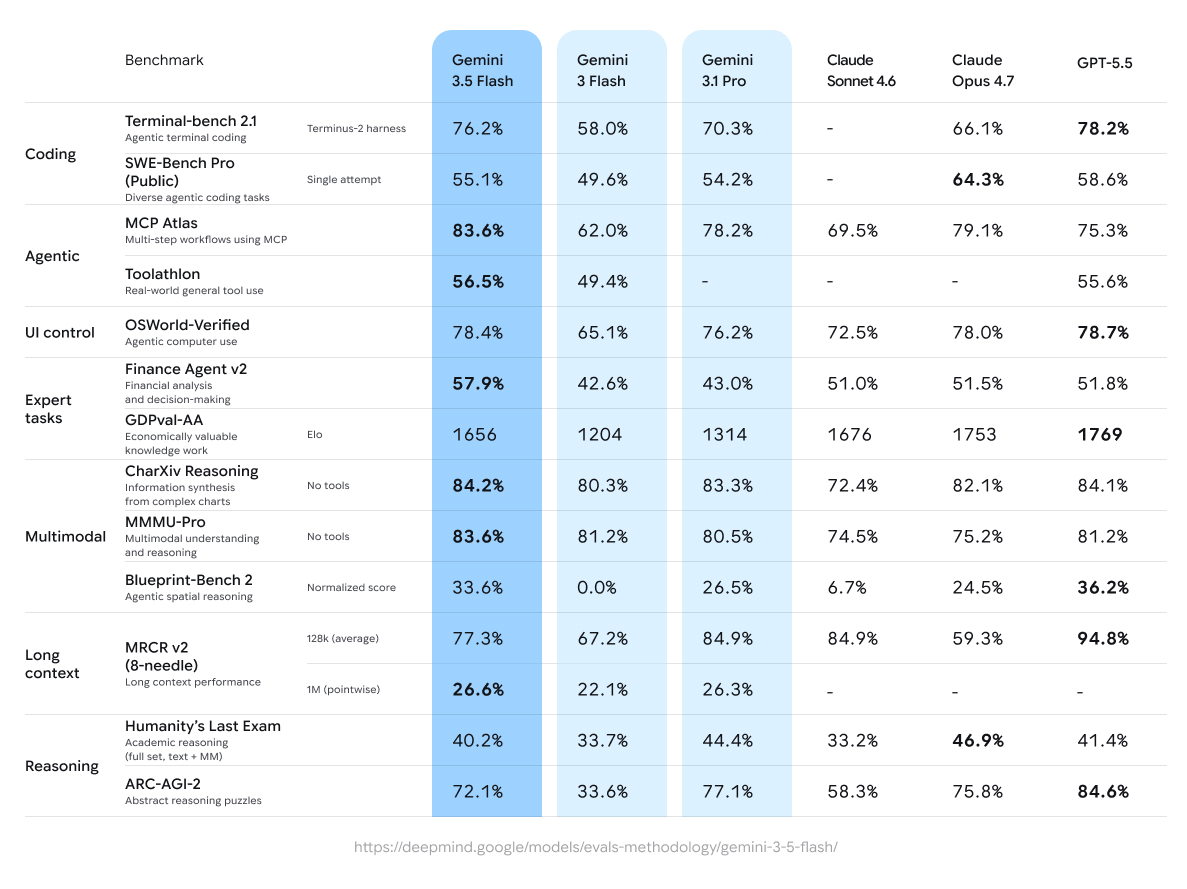
A key difference is dynamic thinking, which automatically allocates more compute when a task is more complex. This helps balance speed and reasoning quality without requiring developers to manually tune model behavior for every request.
It also comes at half the cost, or less, of comparable frontier models. Early enterprise deployments from Shopify for merchant analytics, Macquarie Bank for document reasoning, and Salesforce for enterprise automation show how the model can be applied in production use cases.
Gemini 3.5 Flash First Test with GPT, Claude and Mistral
We ran a production coding task across four models on Eden AI - a Python function requiring type hints, date filtering, and edge case handling.
Here is the prompt:
“You are a senior backend developer. Write a Python function that:
- Takes a list of JSON objects representing invoices (fields: id, amount, currency, date, status)
- Filters only unpaid invoices from the last 30 days
- Returns a summary dict with: total_amount_due, count, oldest_unpaid_date
Include type hints and handle edge cases (empty list, missing fields).”
Here are the results:
Gemini 3.5 Flash looks slowest and most expensive at first glance - but it generated 7.5x more output than GPT-4.1-mini. On a per-token basis, it was the fastest model in the test.
What the outputs revealed
Two clear tiers emerged from the quality comparison.
Gemini 3.5 Flash and Claude Haiku 4.5 produced deep, production-ready responses.
Gemini was the only model to include a testable reference_date parameter - critical for unit testing without mocking - along with full UTC timezone handling and structured TypedDict return types.
Claude Haiku was the only model to use Decimal for financial precision and return an errors list alongside the result, which matters for observability in production pipelines.
Mistral Small and GPT-4.1-mini returned byte-for-byte identical code - correct, clean, and minimal. For a well-scoped standard task, the cheapest models converge on the same answer. At $0.0002 per call, Mistral is the right choice for high-volume, low-complexity workloads.
No single model was universally best. Gemini 3.5 Flash and Claude Haiku each caught edge cases the other missed. This is exactly the decision Eden AI lets you make per use case - not per vendor contract.
Why use Gemini 3.5 Flash through Eden AI?
Using Gemini 3.5 Flash through Eden AI gives your team access to Google’s latest model alongside 500+ other AI models through a single API. Instead of building and maintaining separate integrations for each provider, you can test, compare, and deploy models from one consistent interface.
For production workloads, Eden AI helps reduce operational risk with:
- Fallback routing: If Gemini 3.5 Flash is rate-limited or unavailable, Eden AI automatically reroutes your request to a configured fallback model - with no code changes on your side.
- Side-by-side comparison: Run the same prompt through Gemini 3.5 Flash and three other models simultaneously, as we did above. Benchmark quality, latency, and cost for your specific workload before committing.
- No vendor lock-in: Switching from one model to another on Eden AI requires changing a single parameter - not rebuilding your integration.
- Unified billing: One invoice across all providers, with per-model cost tracking built in.
- GDPR-compliant options: Route requests through European infrastructure where required.

.jpg)
%20(1).png)

