
Résumez cet article avec :
- Une AI Gateway est une couche intermédiaire d'API qui fournit un endpoint unique et unifié , compatible avec le format d'OpenAI - tout en permettant de router vos requêtes vers différents modèles en arrière-plan.
- Réduction des coûts de 20 à 50 % : en sélectionnant le modèle le plus adapté à chaque tâche, vous évitez d'utiliser systématiquement l'option la plus coûteuse.
- Il montre chaque étape, de la génération de votre clé API Eden AI à l'exécution d'une première tâche Codex avec un modèle d'IA alternatif.
- Lorsque vous installez et configurez Codex , il pointe par défaut vers l'endpoint de l'API OpenAI.
- OpenAI Codex, dans sa version d'agent de coding lancée en 2025, et non l'ancienne API Codex aujourd'hui dépréciée, est un assistant de développement autonome hébergé dans le cloud .
Qu’est-ce qu’OpenAI Codex et pourquoi le choix du modèle est important ?
OpenAI Codex, dans sa version d’agent de coding lancée en 2025, et non l’ancienne API Codex aujourd’hui dépréciée, est un assistant de développement autonome hébergé dans le cloud.
Concrètement, vous lui confiez une tâche : corriger un bug, ajouter une fonctionnalité, écrire des tests. Codex analyse ensuite la base de code, travaille de manière autonome, puis vous livre une pull request prête à être revue.
C’est un outil puissant, mais par défaut, Codex fonctionne uniquement avec les modèles OpenAI.
Pourquoi le choix du modèle est-il si important avec Codex ? Tous les modèles d’IA ne se valent pas selon les cas d’usage. Chaque modèle possède ses propres forces :
- Claude 3.7 Sonnet est souvent très performant pour les tâches de raisonnement complexe et les contextes longs.
- Gemini 2.0 Flash est rapide et économique pour les volumes importants de tâches de développement.
- Mistral Codestral est spécialement conçu pour la génération de code et peut être plus avantageux à grande échelle.
- GPT-4o reste très solide pour les tâches généralistes.
Se limiter à un seul fournisseur signifie que vous ne pouvez pas vraiment optimiser vos coûts, vos performances ou vos cas d’usage spécifiques. Vous payez les tarifs d’OpenAI à chaque requête, même lorsque ce n’est pas forcément le modèle le plus adapté à votre besoin.
The Problem: Codex Is Locked to OpenAI by Default
When you install and configure Codex, it points to OpenAI's API endpoint by default. Every request, every code completion, every agent step goes through OpenAI. There's no built-in option to swap providers.This creates three real problems:
- Cost lock-in. You can't route cheaper tasks to lower-cost models. Everything runs at the same OpenAI pricing tier.
- No fallback. If OpenAI has an outage or rate limit issue, your whole workflow stops. There's no automatic failover.
- No best-model routing. Some models handle certain coding tasks better than others. A locked setup can't take advantage of that.
The fix is an AI Gateway - a layer that sits between Codex and the model providers.
Le problème : Codex est verrouillé sur OpenAI par défaut
Lorsque vous installez et configurez Codex, il pointe par défaut vers l’endpoint de l’API OpenAI. Cela signifie que chaque requête, chaque complétion de code et chaque étape de l’agent passe par OpenAI.
Aujourd’hui, il n’existe pas d’option native pour changer facilement de fournisseur de modèles.
Cette limitation crée trois vrais problèmes :
- Dépendance aux coûts OpenAI : vous ne pouvez pas router les tâches simples ou moins critiques vers des modèles plus économiques. Toutes les requêtes sont traitées au même niveau de tarification OpenAI.
- Absence de fallback : si OpenAI rencontre une panne, une latence importante ou une limite de débit, tout votre workflow peut être bloqué. Il n’y a pas de bascule automatique vers un autre fournisseur.
- Pas de routage vers le meilleur modèle : certains modèles sont plus adaptés que d’autres à des tâches de développement spécifiques. Avec une configuration verrouillée, vous ne pouvez pas tirer parti du meilleur modèle selon le cas d’usage.
La solution consiste à utiliser une AI Gateway : une couche intermédiaire placée entre Codex et les différents fournisseurs de modèles. Elle permet de rediriger les requêtes vers plusieurs modèles d’IA, d’optimiser les coûts, de mettre en place un fallback et de choisir le modèle le plus pertinent selon la tâche.
Qu’est-ce qu’une AI Gateway et comment fonctionne-t-elle avec Codex ?
Une AI Gateway est une couche intermédiaire d’API qui fournit un endpoint unique et unifié, compatible avec le format d'OpenAI - tout en permettant de router vos requêtes vers différents modèles en arrière-plan.
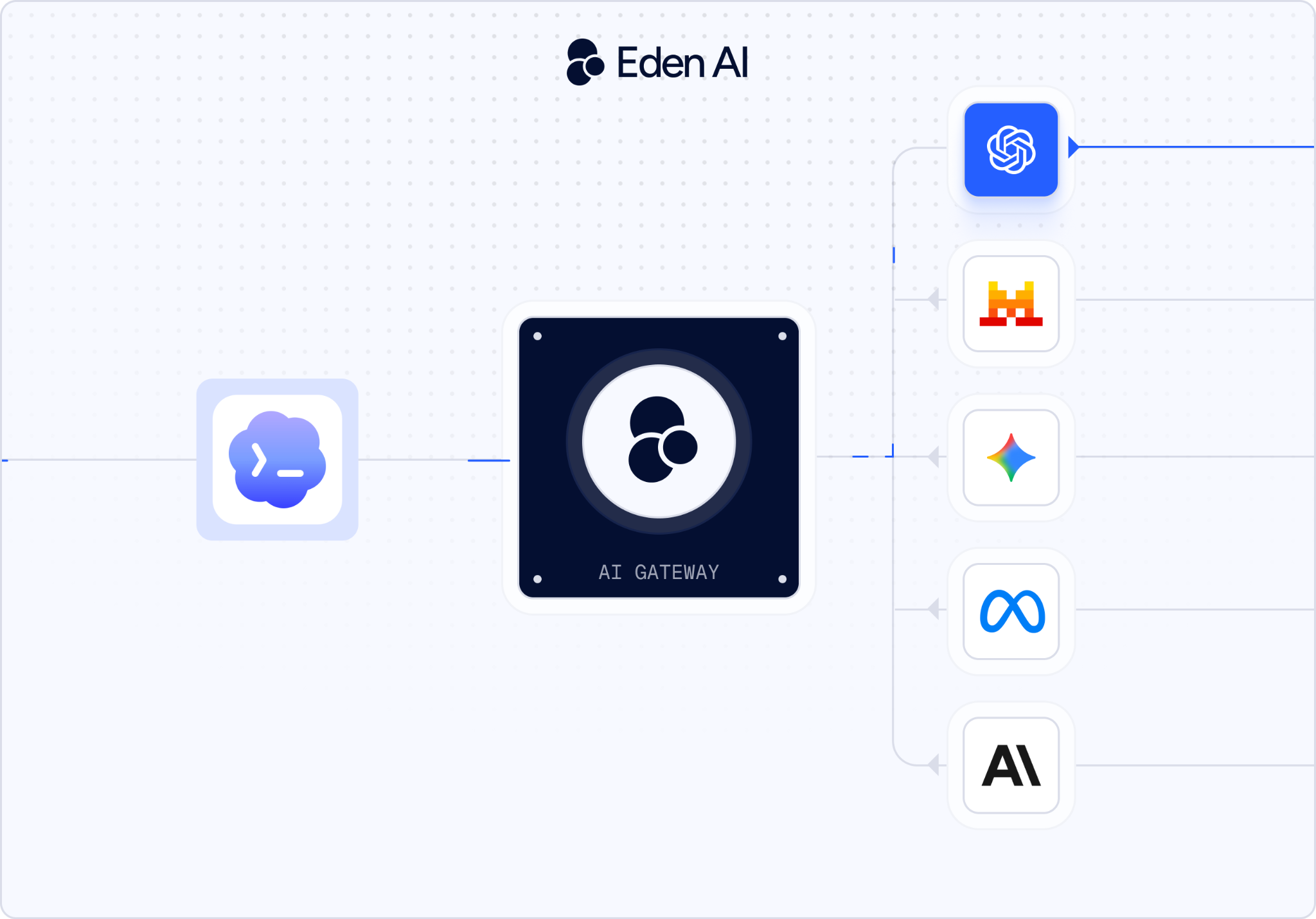
Concrètement, comme la gateway respecte la spécification de l’API OpenAI, Codex ne sait pas qu’il communique avec un autre fournisseur. Il suffit de modifier deux éléments dans votre configuration : la base URL et la clé API.
Eden AI est une AI Gateway qui vous donne accès à plus de 500 modèles d’IA provenant de plus de 50 fournisseurs, à travers une seule API.
Au-delà de l’accès aux modèles, Eden AI permet de gérer plusieurs éléments clés :
- Fallback automatique : lorsqu’un modèle principal atteint une limite de débit, devient indisponible ou rencontre une erreur, Eden AI redirige automatiquement la requête vers le modèle suivant défini dans vos préférences. Vos sessions restent ainsi fluides et ininterrompues.
- Routage intelligent : vous pouvez distribuer les requêtes selon vos objectifs de coût, vos exigences de latence ou la complexité de chaque tâche.
- Suivi des coûts : le dashboard offre une visibilité en temps réel sur les dépenses par modèle, fournisseur et session.
- Réduction des coûts de 20 à 50 % : en sélectionnant le modèle le plus adapté à chaque tâche, vous évitez d’utiliser systématiquement l’option la plus coûteuse.
Pour Codex, cela signifie que vous pouvez simplement connecter l’agent à l’endpoint d’Eden AI, choisir un modèle, puis changer de fournisseur à tout moment sans modifier à nouveau votre configuration Codex.
Étape par étape : connecter Codex à une AI Gateway en 5 minutes
Les étapes ci-dessous vous accompagnent dans toute la configuration, de la création de votre clé API Eden AI jusqu’au lancement de votre première tâche Codex via la gateway. Si vous préférez suivre le processus en vidéo, vous pouvez consulter le tutoriel complet disponible ci-dessus. Il montre chaque étape, de la génération de votre clé API Eden AI à l’exécution d’une première tâche Codex avec un modèle d’IA alternatif.
Vous voulez passer directement au code ? La configuration complète ainsi que des snippets prêts à l’emploi sont disponibles sur notre GitHub.
Quel modèle utiliser ? Claude vs Gemini vs Mistral avec Codex
Il n’existe pas de réponse universelle : le meilleur modèle dépend de ce que vous demandez à Codex de faire.
Voici une comparaison pratique, basée sur des cas d’usage courants en développement.
Claude 3.7 Sonnet : idéal pour les tâches complexes sur plusieurs fichiers
Claude 3.7 Sonnet gère très bien les contextes longs. Si vous demandez à Codex de raisonner sur une grande base de code, de refactorer une logique complexe ou de gérer un changement d’architecture, Claude est souvent le choix le plus performant.
À utiliser lorsque : la tâche nécessite de comprendre beaucoup de code existant avant de proposer des modifications.
Limite : coût par token plus élevé que les modèles de type Flash.
Gemini 1.5 Flash : idéal pour la vitesse et l’optimisation des coûts
Gemini 1.5 Flash est rapide et généralement beaucoup moins coûteux par token. Pour les tâches à fort volume comme l’écriture de tests, la génération de boilerplate ou les petites modifications ciblées, il offre un très bon rapport performance/prix.
À utiliser lorsque : vous exécutez Codex à grande échelle ou sur des tâches répétitives où la vitesse de réponse est importante.
Limite : moins fiable sur les tâches très ambiguës ou les changements d’architecture complexes.
Mistral Large : idéal pour la planification et l’analyse
Mistral Large fonctionne bien en mode planification, notamment pour les tâches de raisonnement en lecture seule où Codex analyse la base de code et définit une stratégie avant d’écrire du code.
C’est une bonne option pour les équipes qui veulent maîtriser leurs coûts sans utiliser systématiquement le modèle le plus puissant à chaque étape.
À utiliser lorsque : vous lancez Codex sur une phase de planification ou d’analyse, plutôt que sur de la génération de code pure.
Limite : moins optimisé pour la génération de code brute que les modèles spécialement entraînés pour le coding.
GPT-4o : idéal pour les tâches généralistes avec les avantages d’une Gateway
Si vous souhaitez conserver une expérience proche de Codex par défaut, tout en bénéficiant du fallback automatique, du suivi des coûts et du routage intelligent, GPT-4o via Eden AI est une option solide.
À utiliser lorsque : vous êtes satisfait des modèles OpenAI, mais souhaitez ajouter plus de fiabilité, de visibilité sur les coûts et de flexibilité à votre configuration.
Conclusion
OpenAI Codex est un agent de coding puissant, mais l’utiliser avec un seul fournisseur limite votre flexibilité, augmente vos coûts et vous laisse sans solution de repli en cas de panne, de limite de débit ou de problème de disponibilité.
Avec Eden AI, vous supprimez cette contrainte en quelques minutes. Il suffit de modifier la base URL, d’ajouter votre clé API Eden AI, et vous accédez immédiatement à plus de 500 modèles d’IA issus de plus de 50 fournisseurs, avec routage intelligent, fallback automatique et suivi complet des coûts intégrés.




.png)