
Résumez cet article avec :
- LiteLLM convient aux équipes qui recherchent un contrôle total de leur infrastructure et disposent de ressources DevOps ou d’une équipe plateforme pour assurer son exploitation.
- Une passerelle IA hébergée offre généralement un coût total de possession plus faible pour les petites et moyennes équipes, une fois intégrés le temps d’ingénierie, les astreintes, les mises à jour, Redis, PostgreSQL et le monitoring.
- L’auto-hébergement de LiteLLM peut devenir plus rentable à très grande échelle, notamment lorsque l’entreprise dispose déjà de l’infrastructure et des compétences nécessaires.
- Eden AI va au-delà d’une passerelle LLM classique en donnant accès, via une API unique, à l’OCR, la reconnaissance vocale, la traduction, la vision, l’analyse de documents et la génération d’images.
- Le choix dépend principalement de vos priorités : optez pour LiteLLM si le contrôle, l’hébergement sur site ou les économies à grande échelle sont essentiels ; choisissez une passerelle hébergée pour réduire la charge opérationnelle, les risques de sécurité et le délai de mise en production.
En mars 2026, les versions malveillantes 1.82.7 et 1.82.8 de LiteLLM ont été publiées sur PyPI dans le cadre d’une attaque visant la chaîne d’approvisionnement logicielle. Les paquets compromis contenaient un logiciel malveillant capable de dérober des identifiants et des données sensibles, d’exécuter du code à distance et d’installer des mécanismes de persistance sur les systèmes affectés. Ils ont ensuite été supprimés et placés en quarantaine par PyPI.
Cet incident met en évidence l’un des principaux compromis liés à une infrastructure IA auto-hébergée. LiteLLM offre aux équipes un contrôle étendu sur le déploiement, le routage des modèles et les flux de données. En contrepartie, elles doivent prendre en charge la sécurité, l’application des correctifs, la supervision, la disponibilité du service et la gestion des incidents.
Une passerelle IA hébergée permet de réduire cette charge opérationnelle, mais implique d’autres compromis en matière de coûts, de personnalisation, de contrôle de l’infrastructure et de dépendance envers un fournisseur.
Ce guide compare LiteLLM et les passerelles IA hébergées selon leur coût total de possession, leur niveau de sécurité, leur fiabilité, leurs fonctionnalités et les efforts nécessaires à la migration. L’objectif est d’aider les équipes à choisir l’approche la plus durable à mesure que leur trafic, leurs besoins techniques et leurs exigences de conformité augmentent.
Qu’est-ce que LiteLLM ? SDK, proxy et positionnement
LiteLLM désigne deux outils open source complémentaires : le SDK LiteLLM, qui s’exécute directement dans une application Python, et le LiteLLM Proxy, une passerelle IA auto-hébergée déployée entre les applications et les fournisseurs de modèles d’intelligence artificielle.
Ces deux solutions permettent d’accéder à plus de 100 modèles de langage (LLM) proposés par des fournisseurs comme OpenAI, Anthropic, Google, Cohere, AWS Bedrock et Microsoft Azure. La principale différence réside dans la responsabilité opérationnelle. Avec le LiteLLM Proxy, votre équipe doit gérer le déploiement, les identifiants d’accès, les mises à jour, le monitoring, la montée en charge, la disponibilité du service et la réponse aux incidents.
LiteLLM convient donc particulièrement aux équipes qui recherchent un contrôle total de leur infrastructure IA et qui disposent déjà de ressources DevOps ou d’une équipe plateforme suffisante. Sa flexibilité constitue un avantage important, mais son coût opérationnel augmente avec le trafic, les exigences de sécurité et les attentes en matière de fiabilité.
Qu’est-ce qu’une passerelle IA hébergée ?
Une passerelle IA hébergée est une couche d’API managée qui une application à plusieurs modèles et fournisseurs d’intelligence artificielle. Grâce à une intégration unique, les développeurs peuvent envoyer des requêtes, changer de modèle, suivre leur consommation et gérer les différences propres à chaque fournisseur, sans avoir à déployer ni à maintenir l’infrastructure de la passerelle.
Architecture hébergée ou auto-hébergée :
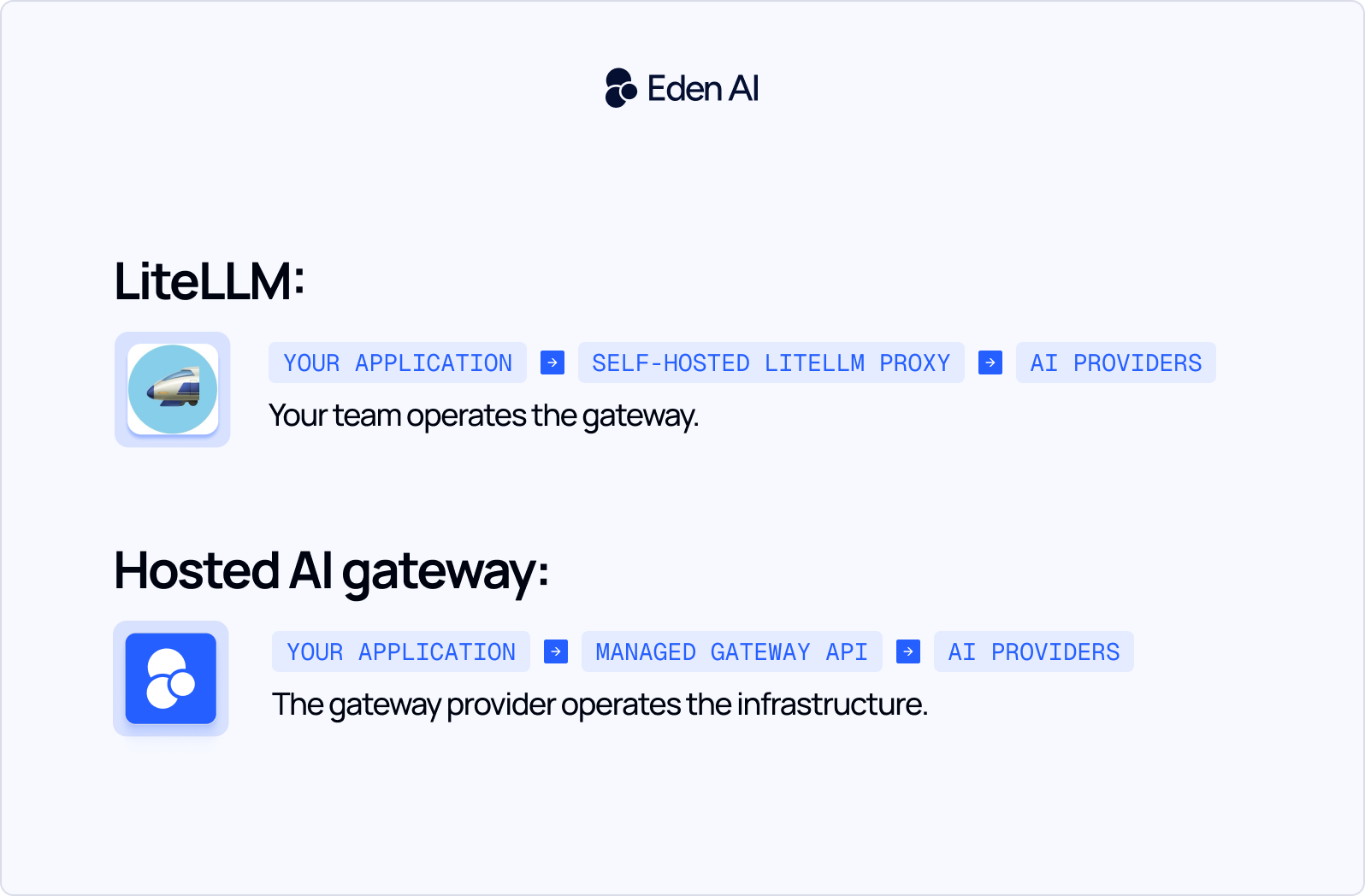
Eden AI est un exemple de passerelle IA hébergée. La plateforme propose une API unifiée donnant accès à plus de 100 modèles d’intelligence artificielle, tout en centralisant l’authentification, la gestion des fournisseurs, le routage des requêtes et le suivi de la consommation.
Son périmètre va au-delà des API de chat et de génération de texte basées sur les LLM. Eden AI prend également en charge des fonctionnalités telles que l’OCR, l’analyse de documents, la transcription audio, la synthèse vocale, la traduction, la génération d’images et la vision par ordinateur.
Eden AI se positionne ainsi comme une passerelle de services d’intelligence artificielle, plutôt que comme un simple proxy LLM. Les équipes peuvent gérer plusieurs charges de travail IA depuis une même plateforme, au lieu d’intégrer et de maintenir un fournisseur ou une passerelle distincte pour chaque fonctionnalité.
La facturation d’Eden AI est basée sur l’usage et liée à la consommation des fournisseurs d’IA, sans obliger les clients à déployer, exploiter ou maintenir une infrastructure de passerelle séparée.
Les 5 principaux compromis entre une passerelle IA auto-hébergée et une solution managée
1. Coût total de possession
LiteLLM est gratuit à installer, mais son utilisation en production nécessite une infrastructure adaptée, des outils de monitoring, des bases de données, l’automatisation des déploiements et du temps d’ingénierie. Une passerelle IA managée remplace une grande partie de ces coûts opérationnels fixes par une tarification basée sur l’usage.
Verdict : l’auto-hébergement est plus économique lorsque votre entreprise dispose déjà de ressources DevOps ou d’une équipe plateforme disponible. Dans le cas contraire, une infrastructure managée peut offrir un coût total de possession inférieur.
2. Sécurité et risques liés à la chaîne d’approvisionnement
Avec une passerelle auto-hébergée, votre équipe est responsable des paquets logiciels, des images de conteneurs, des dépendances, de l’analyse des vulnérabilités, de la gestion des identifiants et de la réponse aux incidents.
Une passerelle IA hébergée prend en charge cette couche logicielle. Il reste toutefois essentiel d’évaluer ses certifications, ses politiques de conservation des données, ses sous-traitants et ses procédures de sécurité.
Verdict : choisissez l’auto-hébergement pour conserver un contrôle maximal. Optez pour une solution managée afin de réduire les responsabilités liées à la sécurité de la chaîne d’approvisionnement.
3. Charge opérationnelle
Running LiteLLM in production requires upgrades, scaling, databases, caching, monitoring, high availability, and on-call Exploiter LiteLLM en production implique de gérer les mises à jour, la montée en charge, les bases de données, la mise en cache, le monitoring, la haute disponibilité et les astreintes.
Une passerelle hébergée élimine la majorité des tâches liées à l’infrastructure du gateway. Votre équipe doit néanmoins continuer à surveiller la qualité des modèles, la latence et les dépenses liées aux API d’intelligence artificielle.
Verdict : l’auto-hébergement est pertinent lorsque l’exploitation de la passerelle peut être intégrée aux responsabilités d’une équipe plateforme existante.
4. Étendue des fonctionnalités
LiteLLM est principalement conçu pour les charges de travail liées aux LLM, notamment le chat, les embeddings et le reranking.
Eden AI couvre également d’autres catégories de services d’intelligence artificielle, comme l’OCR, l’analyse de documents, la reconnaissance et la synthèse vocales, la traduction, la génération d’images et la vision par ordinateur, accessibles via une API unique.
Verdict : choisissez LiteLLM pour une infrastructure centrée sur les LLM. Choisissez Eden AI lorsque votre application nécessite plusieurs catégories de services IA.
5. Latence et fiabilité
L’auto-hébergement permet de contrôler les régions de déploiement, le dimensionnement de l’infrastructure et l’optimisation des performances. En contrepartie, votre équipe devient responsable de la disponibilité, de l’autoscaling et des mécanismes de basculement.
Une passerelle IA managée ajoute une dépendance supplémentaire à votre architecture, mais réduit les efforts nécessaires pour garantir la fiabilité et assurer la maintenance du service.
Verdict : choisissez LiteLLM pour bénéficier d’un contrôle maximal sur les performances. Préférez une infrastructure managée lorsque la réduction du risque opérationnel est plus importante que le gain potentiel de quelques millisecondes.
Le coût réel de LiteLLM en production
LiteLLM est gratuit à installer, mais son exploitation en production génère des coûts liés à l’infrastructure, au temps d’ingénierie, au support et aux risques opérationnels. À fournisseur et modèle identiques, le coût d’utilisation des modèles reste généralement similaire, que les requêtes passent par LiteLLM ou par une passerelle IA managée.
L’infrastructure technique peut ne coûter que 160 à 550 dollars par mois. Cependant, le principal coût caché provient du temps consacré par les équipes techniques au déploiement, aux mises à jour, au monitoring, à la sécurité, à la montée en charge, aux sauvegardes et à la gestion des incidents.
Une passerelle IA managée remplace la majorité de ces coûts opérationnels fixes par des frais de plateforme proportionnels à l’utilisation. Par exemple, une commission de 5,5 % représente 55 dollars pour une consommation mensuelle de modèles de 1 000 dollars, ou 550 dollars pour une consommation de 10 000 dollars.
L’auto-hébergement peut néanmoins rester plus économique lorsque l’entreprise dispose déjà de l’infrastructure requise et de ressources suffisantes au sein de son équipe plateforme. Cette approche peut également être pertinente en cas de volumes très élevés, d’exigences de déploiement sur site ou de besoin de contrôle total sur l’infrastructure.
À retenir : comparez le coût annuel réel d’exploitation de LiteLLM aux frais payés pour éviter cette charge opérationnelle, et non au prix gratuit de sa licence.
Comparatif des fonctionnalités : LiteLLM vs Eden AI et les autres passerelles IA
Un comparatif pertinent entre LiteLLM et les autres passerelles IA doit distinguer le niveau de contrôle sur le déploiement de l’étendue fonctionnelle de la plateforme. LiteLLM, Eden AI, Portkey et Helicone peuvent tous s’intercaler entre une application et plusieurs fournisseurs de modèles, mais chaque solution répond à des enjeux opérationnels différents.
LiteLLM privilégie le contrôle de l’infrastructure. Il convient particulièrement aux équipes qui souhaitent gérer elles-mêmes le déploiement, les identifiants des fournisseurs, les règles de routage et les flux de données. À grande échelle, LiteLLM peut également devenir économiquement avantageux, à condition que l’entreprise dispose déjà des ressources nécessaires en ingénierie plateforme. En contrepartie, la gestion de l’infrastructure, des mises à jour, de la sécurité et de la disponibilité reste entièrement à la charge de l’équipe.
Eden AI se différencie par l’étendue de ses services. Le choix entre LiteLLM et Eden AI ne se limite donc pas à opposer une solution auto-hébergée à une passerelle managée. Eden AI agit comme une passerelle de services IA complète, couvrant les LLM, mais aussi l’OCR, la voix, la traduction, la vision par ordinateur et la génération d’images.
Portkey est principalement orienté vers le routage en entreprise, la gouvernance, les garde-fous et la flexibilité de déploiement. Helicone est particulièrement adapté lorsque les besoins prioritaires concernent l’observabilité, le débogage, l’évaluation des modèles et l’analyse détaillée des requêtes.
La meilleure passerelle LLM dépend donc des priorités de l’équipe : contrôle de l’infrastructure avec LiteLLM, couverture étendue des services IA avec Eden AI, gouvernance d’entreprise avec Portkey ou visibilité approfondie sur la production avec Helicone.
LiteLLM ou passerelle IA hébergée : quelle solution choisir ?
Le bon choix dépend moins du nombre de fonctionnalités disponibles que de la capacité opérationnelle de votre équipe, de vos exigences de conformité et de votre besoin de contrôle sur l’infrastructure.
Startups en phase d’amorçage ou de démarrage
Une passerelle IA hébergée constitue généralement l’option la plus pragmatique lorsqu’aucune équipe DevOps ou plateforme dédiée n’est disponible. Elle permet aux développeurs d’intégrer une API unique et de se concentrer sur le développement du produit, plutôt que sur l’exploitation d’un proxy, des bases de données, du monitoring et des mises à jour.
Pour une petite équipe, une solution managée réduit généralement le délai de mise en production et la charge opérationnelle.
Entreprises en série A et en phase de croissance
À ce stade, il devient essentiel de comparer le coût total de l’auto-hébergement avec la tarification d’une passerelle managée. LiteLLM peut être pertinent lorsqu’une équipe plateforme expérimentée dispose des compétences et du temps nécessaires pour l’exploiter correctement.
Dans le cas contraire, les coûts liés à la maintenance, à la sécurité et aux astreintes peuvent rendre une passerelle hébergée plus économique.
La décision doit reposer sur le coût total de possession, et non uniquement sur le prix de la licence ou de l’infrastructure.
Grandes entreprises et organisations réglementées
La décision doit commencer par l’analyse des contraintes de conformité et de déploiement. Un fournisseur managé peut proposer des contrôles de sécurité, des fonctions d’audit, une gestion avancée des accès et des accords de niveau de service contractuels.
L’auto-hébergement peut toutefois rester indispensable pour répondre à des exigences strictes de déploiement sur site, de cloud souverain ou d’environnement isolé du réseau.
Règle de décision : choisissez LiteLLM lorsque la maîtrise de l’infrastructure est indispensable et que votre équipe plateforme dispose des ressources nécessaires pour l’exploiter. Optez pour une passerelle IA hébergée lorsque le temps d’ingénierie doit être consacré en priorité au développement du produit.
Comment migrer de LiteLLM vers Eden AI avec du code
Migrer de LiteLLM vers Eden AI ne nécessite pas de réécrire entièrement votre application. Pour une intégration de chat classique, les principaux changements concernent l’authentification, l’URL de l’API et l’identifiant du modèle.
Ne publiez jamais votre clé API dans votre dépôt Git ou dans un fichier accessible publiquement.
Étape 1 : récupérer votre clé API Eden AI
Créez un compte Eden AI, puis générez une clé API depuis le tableau de bord. Stockez cette clé dans une variable d’environnement plutôt que de l’ajouter directement à votre code source.
Étape 2 : remplacer l’appel à LiteLLM
Avant la migration, votre application envoie ses requêtes via le SDK Python de LiteLLM :
import litellm
response = litellm.completion(
model="gpt-4o",
messages=[
{"role": "user", "content": "Summarize this contract."}
]
)
summary = response.choices[0].message.content
Après la migration, envoyez la même conversation vers le point de terminaison d’Eden AI compatible avec l’API OpenAI :
import os
import requests
response = requests.post(
"https://api.edenai.run/v3/chat/completions",
headers={
"Authorization": f"Bearer {os.environ['EDENAI_API_KEY']}",
"Content-Type": "application/json",
},
json={
"model": "openai/gpt-4o",
"messages": [
{
"role": "system",
"content": "You are a contract analyst.",
},
{
"role": "user",
"content": "Summarize this contract.",
},
],
},
timeout=60,
)
response.raise_for_status()
summary = response.json()["choices"][0]["message"]["content"]
Eden AI utilise un format fournisseur/modèle, par exemple :
openai/gpt-4oanthropic/claude-sonnet-4-5google/gemini-2.5-flash
La réponse suit la structure de l’API OpenAI Chat Completions. La majeure partie du code utilisé pour analyser et traiter les réponses peut donc rester inchangée.
Étape 3 : adapter les règles de routage et de fallback
Remplacez les alias de modèles LiteLLM par les identifiants explicites des modèles disponibles sur Eden AI. Lorsque LiteLLM gérait auparavant les fallbacks, ajoutez des modèles de secours à la requête Eden AI:
"model": "openai/gpt-4o",
"fallbacks": [
"anthropic/claude-sonnet-4-5",
"google/gemini-2.5-flash",
]
Commencez par utiliser le même modèle principal que celui déjà déployé en production. Modifiez ensuite les règles de fallback séparément afin de mesurer précisément leur impact sur la qualité des réponses, la latence et les coûts.
Étape 4 : tester le comportement de l’application
Exécutez les deux intégrations sur un jeu de tests représentatif. Comparez notamment :
- la qualité des réponses ;
- la latence ;
- la consommation de tokens ;
- les erreurs ;
- les sorties structurées ;
- les paramètres propres à chaque fournisseur.
Vérifiez particulièrement les délais d’expiration, les limites de débit, le streaming, les appels d’outils et le code dépendant des classes d’exception spécifiques à LiteLLM.
Une migration réussie doit valider le comportement fonctionnel de l’application, et pas uniquement le bon fonctionnement de la connexion à l’API.
Étape 5 : déployer progressivement la migration
Placez le choix de la passerelle derrière un feature flag ou une variable de configuration. Commencez par envoyer une faible proportion du trafic de production vers Eden AI, surveillez les résultats, puis augmentez progressivement ce pourcentage.
Conservez temporairement le parcours LiteLLM pendant la période de validation afin de pouvoir revenir rapidement à l’ancienne intégration en cas de problème.
Une fois la connexion à Eden AI stabilisée, supprimez progressivement :
- le déploiement du proxy LiteLLM ;
- les ressources Redis et PostgreSQL devenues inutiles ;
- les identifiants des fournisseurs qui ne sont plus utilisés ;
- les règles de monitoring propres à la passerelle ;
- les procédures d’astreinte associées à LiteLLM.
Une migration progressive limite les risques tout en permettant de comparer Eden AI et LiteLLM dans des conditions réelles de production.

.jpg)


